การอ่าน Query Execution Plan ตอนที่ 1
- Microsoft SQL Server Management Studio (SSMS) และ
- Sentryone Plan Explorer
หากผู้อ่านต้องการทำตามตัวอย่างในบทความ ก็สามารถหาดาวน์โหลดได้จาก https://www.sentryone.com/plan-explorer
ประเภทการแสดงผล Query Execution Plan
ขอเรียกว่า Compiled Query Execution Plan หรือ Compiled Plan (รายละเอียดอยู่บทความ “เตรียมพร้อมก่อนอ่าน Execution Plan” สนุกมาก) ซึ่งการแสดงผลแบ่งออกได้ 2 ประเภทดังนี้
- Estimated Execution Plan คือการแสดงผล Query Execution Plan ที่ถูก Compiled แล้วแต่ยังไม่ถูก Execute
- Actual Execution Plan คือการแสดงผลทั้งข้อมูลที่เป็นค่าประเมิน (Estimated) และข้อมูลที่ได้จากการ Execute จริง (Actual)
การแสดงผล Estimated Execution Plan
- แสดงผลเป็นเอกสาร XML ผ่านคำสั่ง SET SHOWPLAN_XML โดยมี Syntax ดังนี้
SET SHOWPLAN_XML { ON | OFF } |
เมื่อเราป้อนคำสั่ง T-SQL ต่อจากการกำหนด SET SHOWPLAN_XML ให้มีค่าเป็น ON แล้วทำการ Execute
จะพบว่า Microsoft SQL Server จะแสดง Compiled Plan ออกมาในรูปแบบเอกสาร XML โดยไม่ประมวลผล Compiled Plan ดังกล่าว
ทดสอบด้วยสคริปต์ต่อไปนี้กับฐานข้อมูล Adventureworks ผ่าน SQL Server Management Studio (SSMS)
SET SHOWPLAN_XML ON GO SELECT E.BusinessEntityID , P.Title , P.FirstName , P.MiddleName , P.LastName , P.Suffix , E.JobTitle , D.Name AS Department , D.GroupName , EH.StartDate FROM HumanResources.Employee as E INNER JOIN Person.Person as P ON P.BusinessEntityID = E.BusinessEntityID INNER JOIN HumanResources.EmployeeDepartmentHistory as EH ON E.BusinessEntityID = EH.BusinessEntityID INNER JOIN HumanResources.Department as D ON EH.DepartmentID = D.DepartmentID WHERE EH.EndDate IS NULL; GO SET SHOWPLAN_XML OFF |
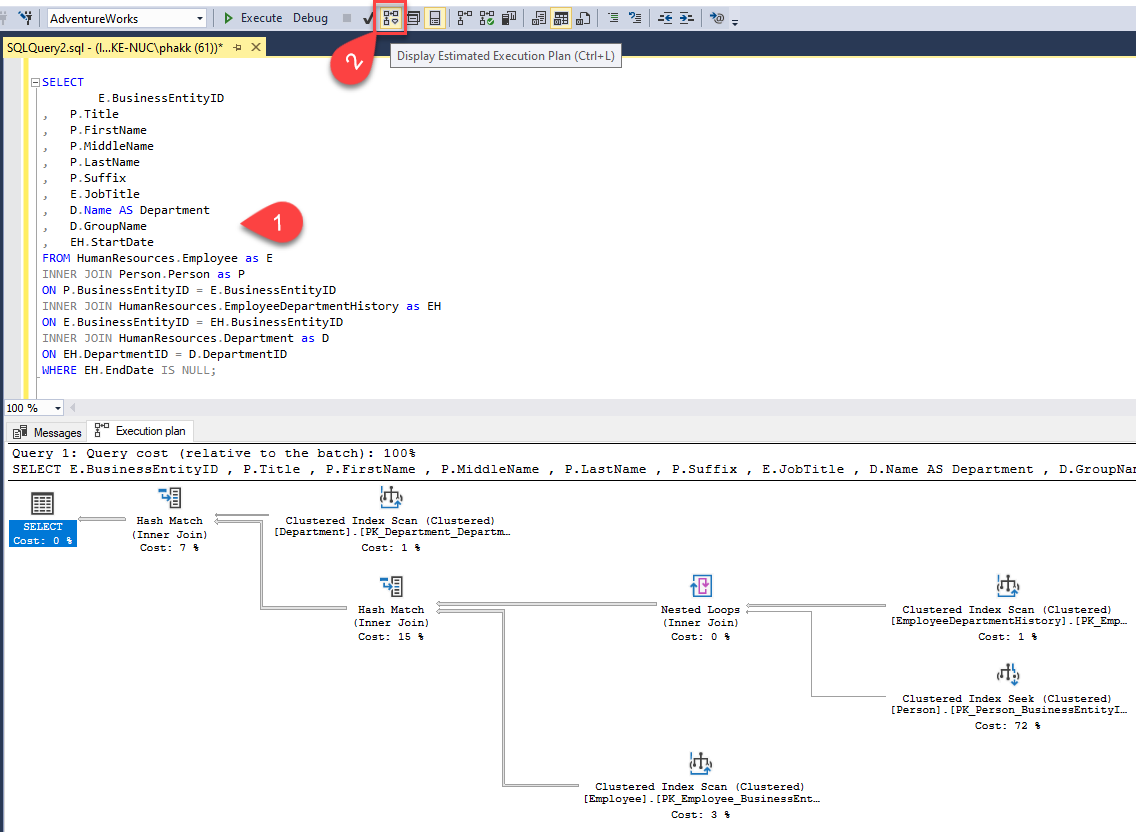
- .แสดงผลเป็น Graphic ทันที ผ่าน SQL Server Management Studio (SSMS)
โดยพิมพ์ Query ที่ต้องการแสดง Compiled Plan เข้าไปจากนั้นกด Ctrl-L หรือ
กดไปที่ปุ่ม Display Estimated Execution Plan จะได้ผลลัพธ์เป็น Complied Plan ออกมาในแท็ป Execution Plan ดังแสดง
การแสดงผล Actual Execution Plan
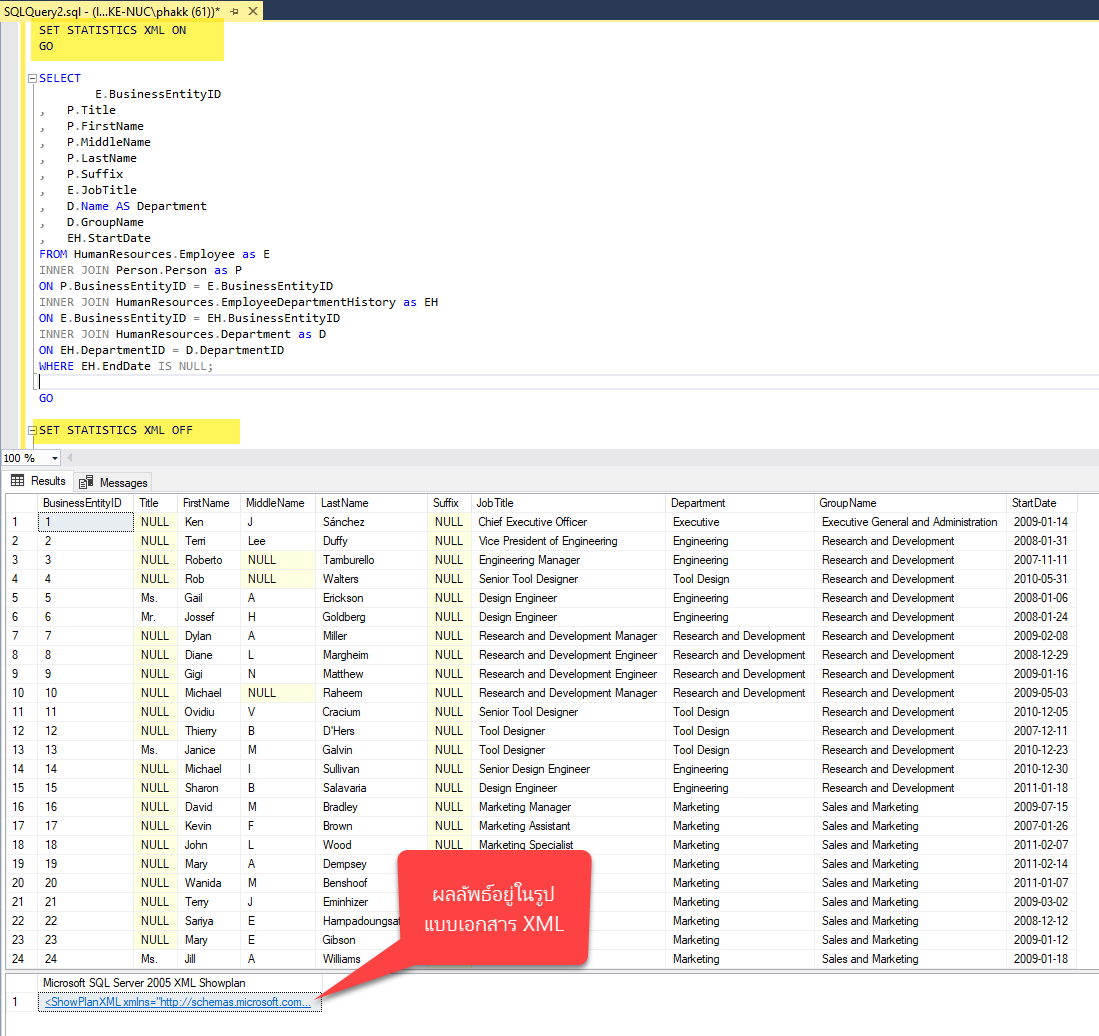
- แสดงผลเป็นเอกสาร XML ผ่านคำสั่ง SET STATISTICS XML โดยมี Syntax ดังนี้
SET STATISTICS XML { ON | OFF } |
เมื่อเราป้อนคำสั่ง T-SQL ต่อจากการกำหนด SET STATISTICS XML ให้มีค่าเป็น ON แล้วทำการ Execute
จะพบว่า Microsoft SQL Server ทำการประมวล Compiled Plan จนได้ Resultset ออกมา
หลังจากนั้นจึงแสดงผล Complied Plan พร้อมข้อมูลที่เกิดตอนประมวลผลจริงในรูปแบบเอกสาร XML
SET STATISTICS XML ON GO SELECT E.BusinessEntityID , P.Title , P.FirstName , P.MiddleName , P.LastName , P.Suffix , E.JobTitle , D.Name AS Department , D.GroupName , EH.StartDate FROM HumanResources.Employee as E INNER JOIN Person.Person as P ON P.BusinessEntityID = E.BusinessEntityID INNER JOIN HumanResources.EmployeeDepartmentHistory as EH ON E.BusinessEntityID = EH.BusinessEntityID INNER JOIN HumanResources.Department as D ON EH.DepartmentID = D.DepartmentID WHERE EH.EndDate IS NULL; GO SET STATISTICS XML OFF |
จะสังเกตเห็นว่าผู้เขียนต้องใช้ประโยค GO เพื่อให้คำสั่ง SET STATISTICS XML อยู่คนละ Scope (Batch) กับคำสั่งอื่น ๆ เพราะเป็นข้อจำกัดของคำสั่งนี้
- แสดงผลเป็น Graphic หลังจาก Execute คำสั่งผ่าน SQL Server Management Studio (SSMS)
โดยจะต้องทำการ Enable โดยกด Ctrl-M หรือกดปุ่ม Include Actual Execution Plan ก่อนจะ Execute ดังแสดง
พบว่าหลังจาก Execute จนได้ Resultset เรียบร้อยแล้วจะปรากฎแท็ป Execution Plan ตามมา
เปรียบเทียบข้อมูลของการแสดงผล Query Execution Plan แต่ละแบบ
ในส่วนของ Estimated Execution Plan นั้นแสดง Compiled Plan ที่ยังไม่ได้ Execute
ค่าต่างๆ ที่ได้มาเกิดจากการคำนวนของคอมโพเนนต์ในกลุ่ม Query Optimization ชื่อ Cardinality Estimator
โดยใช้ข้อมูลหลักจาก Statistics (ในรูปแบบของ Histogram) ที่สัมพันธ์กับแต่ละ Predicate (ในที่นี้คือเงื่อนไขหลังประโยค WHERE) เพื่อประเมินจำนวนแถวข้อมูล (Estimated Number of Rows)
จากนั้นจึงนำไปประเมิน Cost ต่างๆ ต่อไป (Compiled Plan ที่แสดงใน Estimated Execution Plan ถูกเลือกมาแล้ว จาก หลายๆ Plan แข่งขันกันด้วยค่า Cost นี่เอง)
ผู้อ่านจะพบจำนวนแถวข้อมูลที่ได้จากการประมวลผลจริง (Actual Number of Rows) เพิ่มจากค่าประเมิน
หากจำนวนแถวข้อมูลจากการประมวลผล ต่างจากจำนวนแถวข้อมูลที่ได้จากการประเมินมาก เป็นเพราะ Statistics (Histogram) เริ่มไม่สะท้อนค่าปัจจุบัน
อาจจำเป็นต้องปรับปรุง Statistics แบบ Manual (ปกติแล้ว Statistics ถูกตั้งค่าให้ปรับปรุงอัตโนมัติ)
Estimated Execution Plan และ Actual Execution Plan
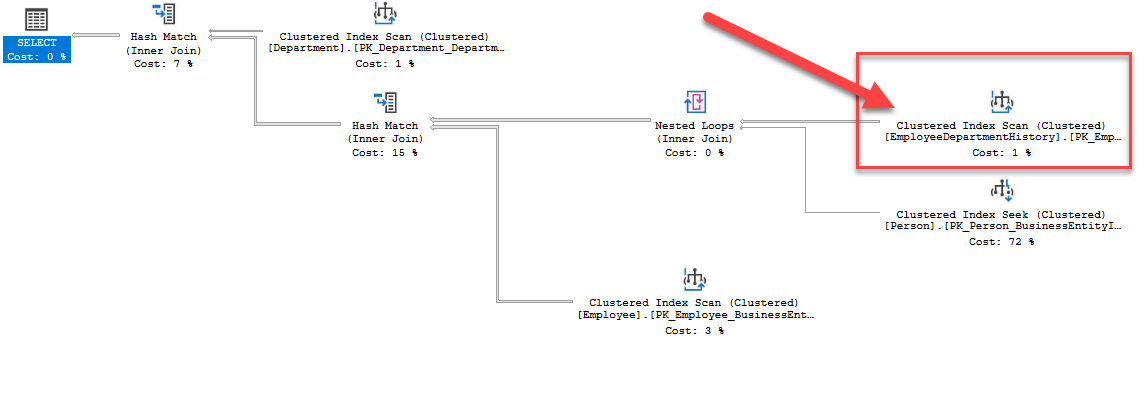
นอกเหนือจากการเอาเม้าส์ไปลอยอยู่เหนือตัวดำเนินการเพื่อแสดงข้อมูลแล้ว ยังสามารถดูรายละเอียดที่มากขึ้น
โดยการคลิกไปที่ตัวดำเนินการใดๆ แล้วกด F4 หรือคลิกขวาเลือก Properties เพื่อแสดง Properties ของตัวดำเนินการนั้นดังแสดง
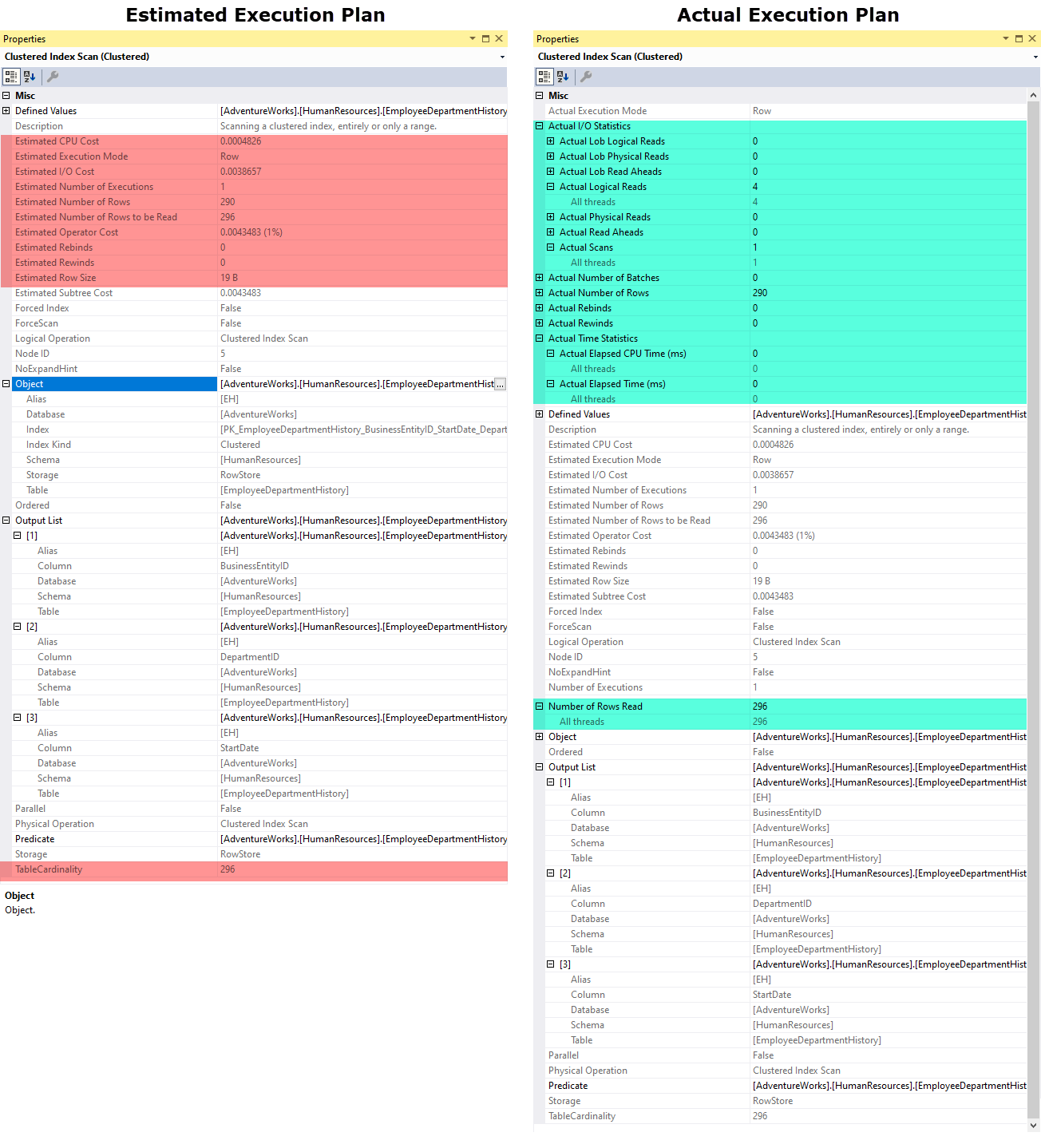
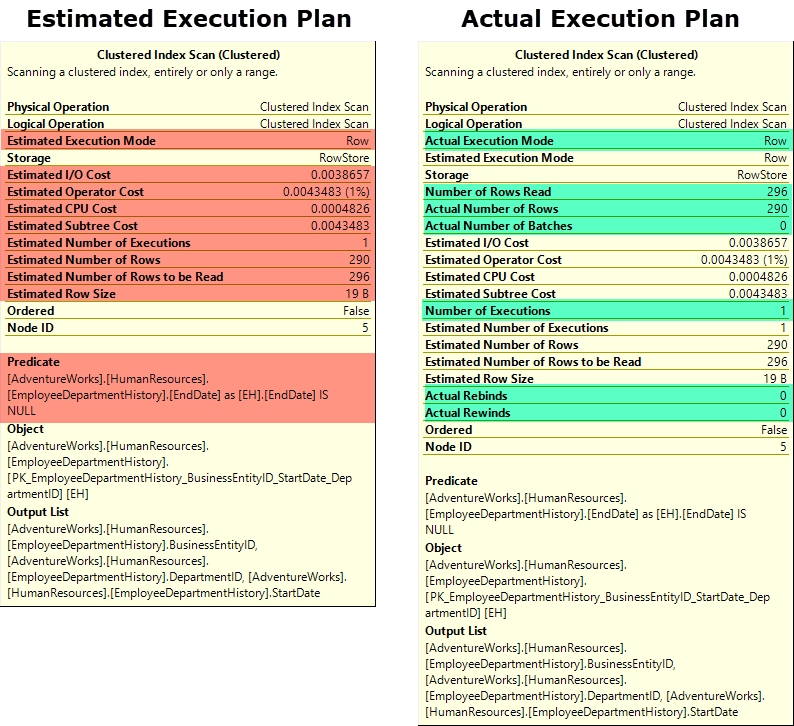
พบว่าการเรียก Properties ขึ้นมาแสดงสามารถให้รายละเอียดที่เพิ่มขึ้น
โดยเฉพาะในส่วนของ Actual Execution Plan จะแสดง I/O Statistics และ Time Statistics ที่ใช้ในการประมวลผล
อีกทั้งเห็นการแตกเป็น Threads ย่อยในการใช้ I/O หรือ CPU อีกด้วย
เส้นเชื่อม (Edge) ระหว่างตัวดำเนินการยังแสดงถึงข้อมูลที่ไหลจากตัวดำเนินการหนึ่งไปยังอีกตัวดำเนินการหนึ่ง ดังแสดง
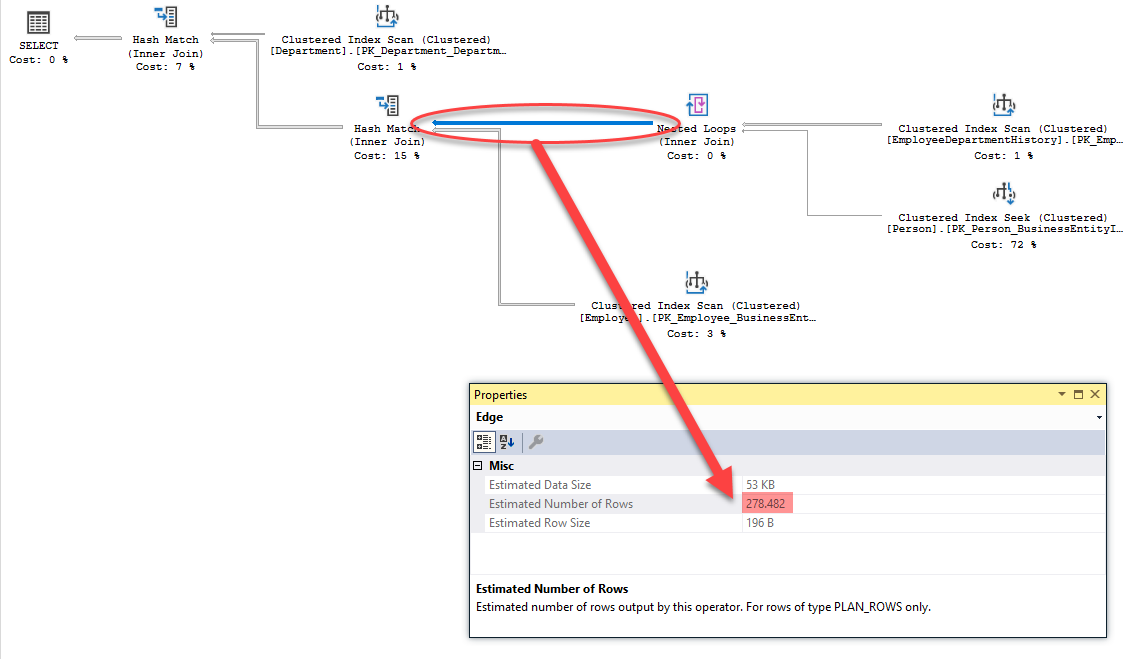
หากนำเม้าส์ไปลอยอยู่เหนือเส้นเชื่อม หรือเรียก Properties ของเส้นเชื่อมออกมา
จะพบกับค่าจำนวนแถวข้อมูลที่ได้จากการประเมินมีค่าเป็น 278.482 เป็นเครื่องยืนยันว่าเป็นการคำนวนเชิงสถิติมา เพราะจำนวนแถวข้อมูลจริงๆ แล้วต้องเป็นจำนวนเต็ม
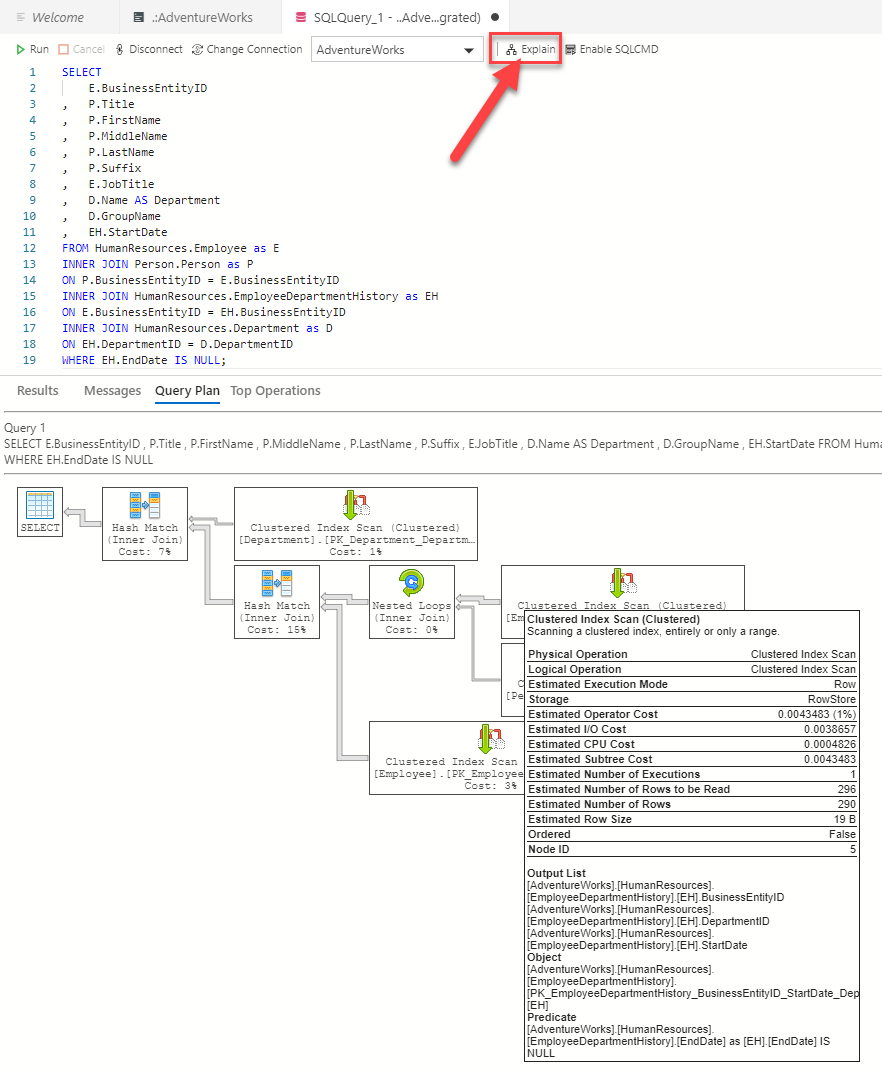
อีกหนึ่งเครื่องมือจาก Microsoft ชื่อ Azure Data Studio ก็สามารถแสดง Compiled Plan ออกมาได้เช่นกัน
โดยกดไปที่ปุ่ม Explain ข้อมูลของ Estimated Execution Plan จะปรากฎออกมาดังแสดง
ผู้อ่านสามารถหาดาวน์โหลดได้จาก https://www.sentryone.com/plan-explorer เป็นซอฟต์แวร์ฟรี มี Plugin สำหรับ SSMS หรือจะใช้อิสระก็สามารถใช้งานได้
แนะนำ SentryOne Plan Explorer
ผู้อ่านสามารถทำความเข้าใจ โดยการทำตามตัวอย่างใน Blogs ต่างๆ ได้
(ทำตามนั้นไม่ยาก แต่การแปลความหมายนั้น ผู้อ่านจำเป็นต้องเข้าใจว่าแต่ละตัวดำเนินการนั้นกระทำบนโครงสร้างข้อมูลแบบใดอยู่ อันนี้อาจต้องเข้มข้นนิดหน่อย)
- ก่อนเริ่มทดสอบการใช้งานผู้เขียนแนะนำให้ลบ Non-Clustered Index บนตาราง Sales.SalesOrderHeader ที่มีคอลัมน์ OrderDate เป็นองค์ประกอบออกก่อน ด้วยสคริปต์ต่อไปนี้
DECLARE @indexName sysname , @myStatement nvarchar(max) DECLARE i_cursor CURSOR FOR SELECT I.name FROM sys.indexes AS I INNER JOIN sys.index_columns AS C ON I.object_id = C.object_id AND I.index_id = C.index_id WHERE I.object_id=OBJECT_ID('Sales.SalesOrderHeader') AND COL_NAME(C.object_id,C.column_id)='OrderDate' OPEN i_cursor FETCH NEXT FROM index_cursor INTO @indexName WHILE @@FETCH_STATUS = 0 BEGIN SET @myStatement = N'DROP INDEX ' + QUOTENAME(@indexname) + 'ON Sales.SalesOrderHeader' EXEC sp_executesql @myStatement FETCH NEXT FROM index_cursor INTO @indexname END CLOSE i_cursor DEALLOCATE i_cursor |
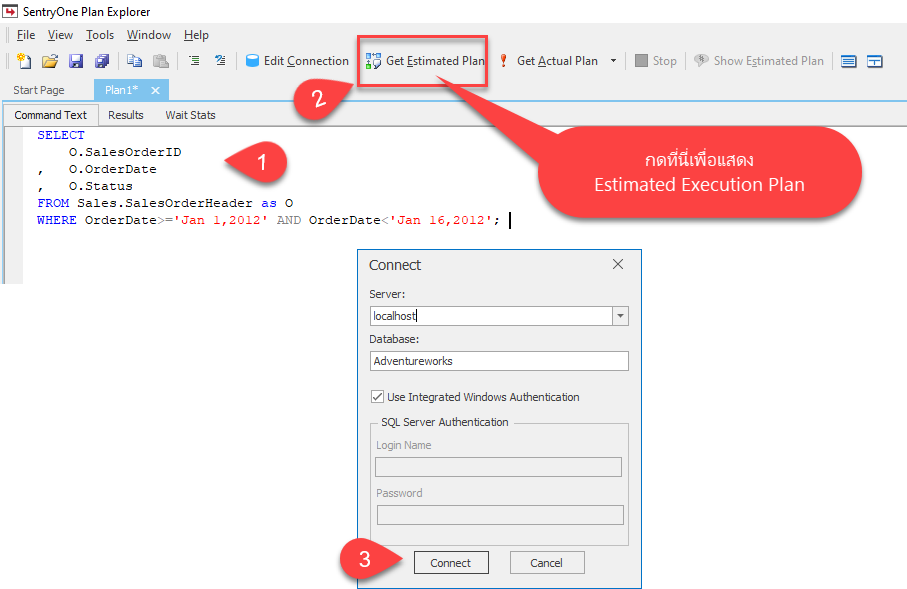
- เริ่มสร้าง Session ขึ้นมาใช้งาน โดยกด New Session ใน Start Page หรือ Menu Bar ก็ได้ เลือกแท็บ Command Text แล้วนำคำสั่งต่อไปนี้ ใสลงไปเพื่อทดสอบ
SELECT O.SalesOrderID , O.OrderDate , O.Status FROM Sales.SalesOrderHeader as O WHERE OrderDate>='Jan 1,2012' AND OrderDate<'Jan 16,2012'; |
- จากนั้นกดไปที่ปุ่ม Get Estimated Plan เพื่อแสดง Estimated Execution Plan
หาก Session ยังไม่ได้เชื่อมต่อไปยังฐานข้อมูลจะปรากฎไดอะล็อก Connect ขึ้นมาให้สร้างการเชื่อมต่อในทำการเชื่อมต่อจนสำเร็จ (ต้องใช้ Login ที่มีสิทธิ์ SHOWPLAN บนฐานข้อมูลเป้าหมาย)
จะได้ผลลัพธ์ออกมาเป็น Compiled Plan ในรูปแบบ Graphic
(หากไม่แสดงผลเป็น Plan ในรูปแบบ Graphic ให้เลือกไปที่แท็บ Plan Diagram)
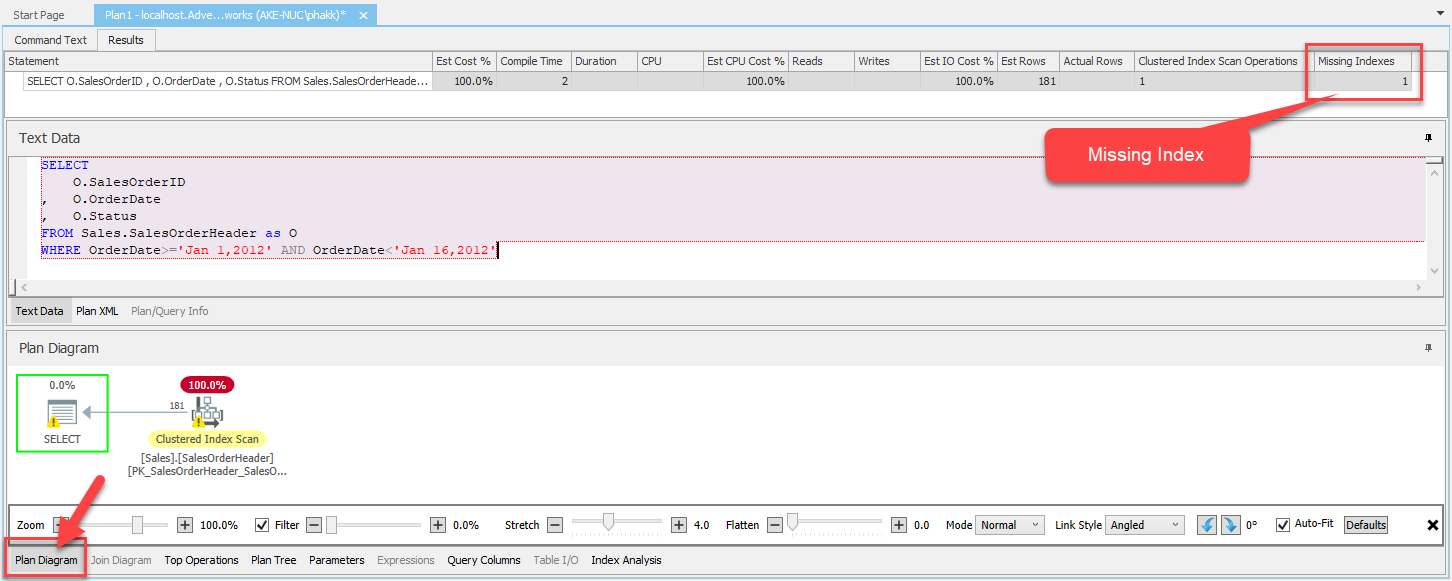
Clustered Index คือโครงสร้างตารางที่มีความเป็น Index รวมอยู่ในตารางเลย
คือข้อมูลแต่ละแถวจะจัดเรียงตามคอลัมน์ที่ถูกเลือกเป็น Clustered Key
ดังนั้นหากตัวดำเนินการเป็น Clustered Index Scan ก็ไม่ได้ต่างอะไรกับ Table Scan เลย
สำหรับตารางนี้ Clustered Key คือคอลัมน์ SalesOrderID
แต่ในประโยค WHERE เป็น Predicate ที่กระทำบนคอลัมน์ OrderDate
ดังนั้น Query Optimizer จึงเลือกที่จะ Scan เอา
(สังเกตว่ามีเครื่องหมาย Warning ปรากฎอยู่) จะแสดงข้อมูลดังนี้
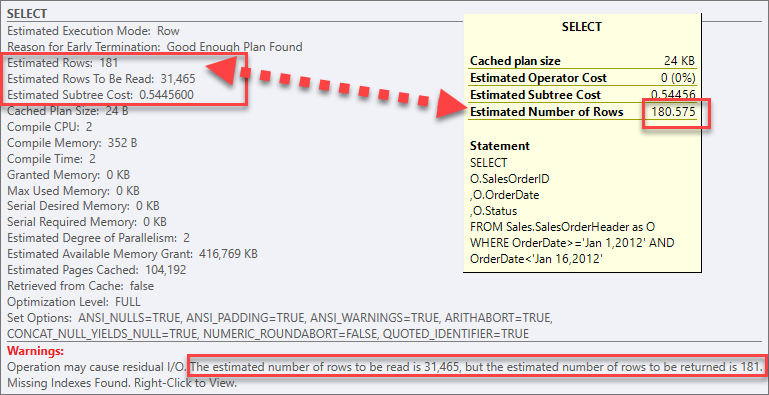
(ที่จริงแล้วคำนวนได้ 180.575 แถว หากดูใน SSMS แต่ SentryOne Plan Explorer มีการปัดขึ้น)
แต่เนื่องจากไม่มี Index ช่วยในการสืบค้นจึงจำเป็นต้อง Scan แถวข้อมูลทั้งสิ้น 31,465 แถวข้อมูล
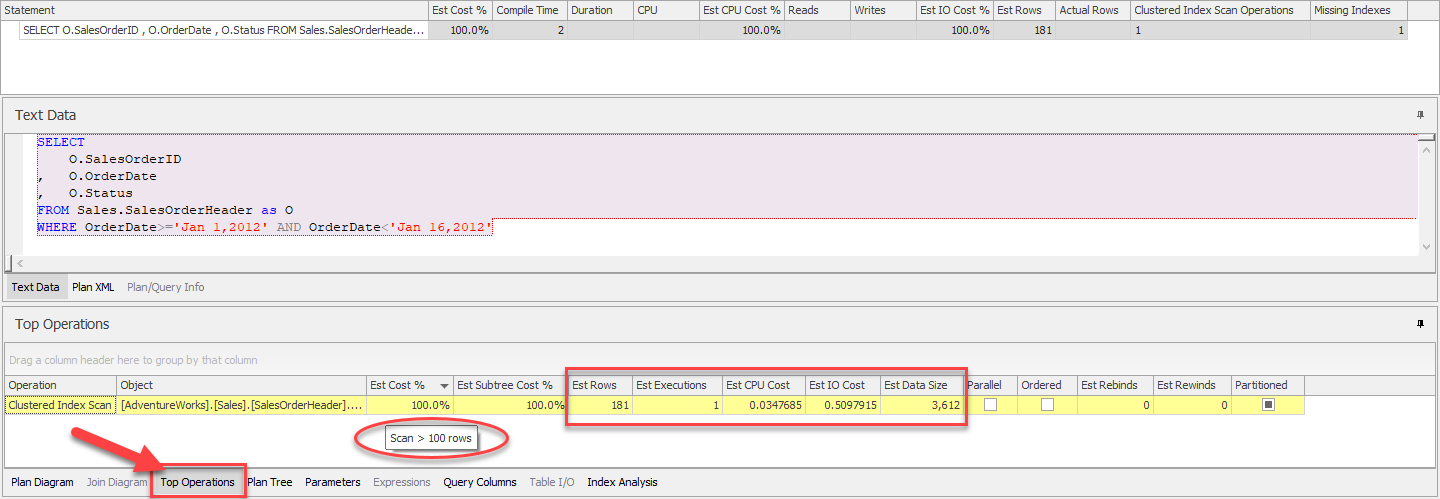
- จากนั้นเลือกไปที่แท็บ Top Operators เนื่องจาก Compiled Plan นี้มีเพียงตัวดำเนินการเดียว จึงมีรายการของตัวดำเนินการเพียงบรรทัดเดียว
โดยไฮไลท์สีเหลืองเอาไว้แสดงถึงการแจ้งเตือนเช่นกัน และยังคงเป็นเหตุผลเดิมคือเกิดการ Scan แถวข้อมูลมากเกิน
(31,465 เกินจากเกณฑ์ที่ตั้งไว้คือ 100 แถวข้อมูล เป็นข้อดีที่ทำให้เราทราบว่าเริ่มส่งผลกระทบต่อประสิทธิภาพ)
อีกทั้งยังแสดงข้อมูลการประเมินอื่นๆ ตามมาอีกด้วย แท็บนี้จะมีประโยชน์มากหากมีหลายตัวดำเนินการ
เพราะสามารถเรียงตามค่าที่เราต้องการจากมากไปหาน้อย
เช่น Estimated Subtree Cost, Estimated CPU Cost หรือ Estimated I/O Cost เป็นต้น
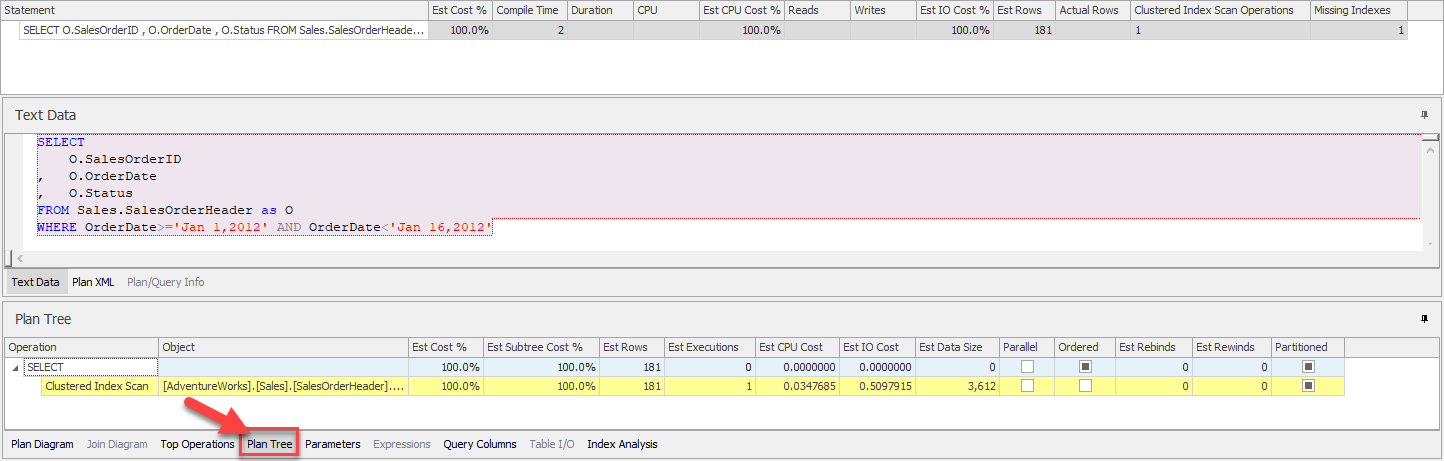
- แท็บถัดมาเป็นแท็บ Plan Tree จะให้ข้อมูลคล้ายคลึงกับแท็บก่อนหน้า แต่จะแสดงในรูปแบบของลำดับชั้นของตัวดำเนินการ
- แท็บถัดมาเป็นแท็บ Parameters เพื่อแสดงพารามิเตอร์ที่ใช้ในคำสั่งในที่นี้คือค่าที่ใช้เปรียบเทียบใน Predicate หลังประโยค WHERE ดังแสดง
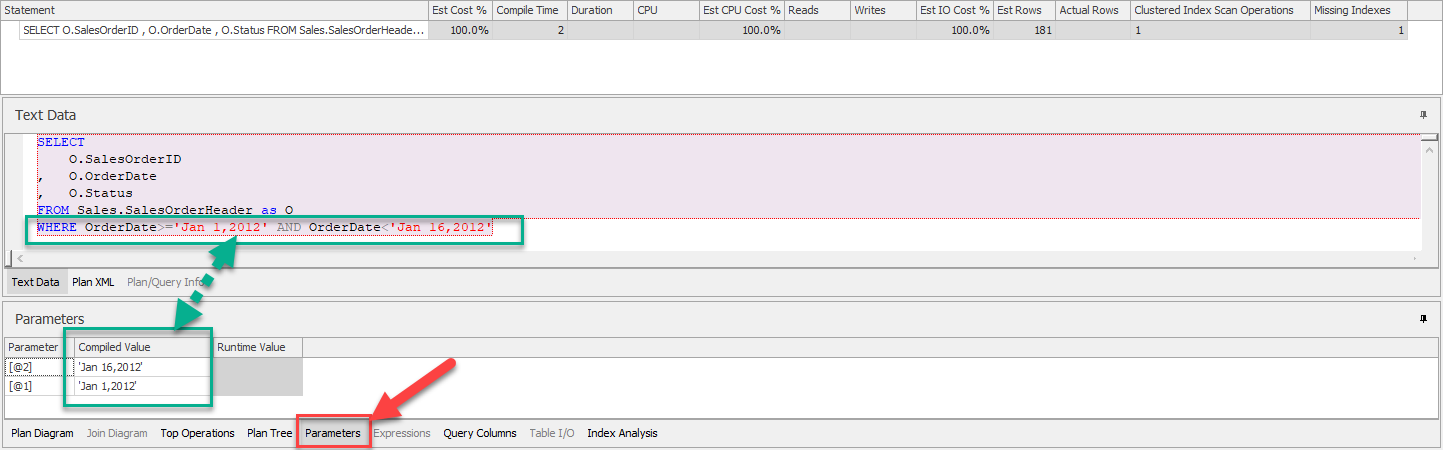
แต่หากเป็นการเรียกดู Actual Execution Plan จะมีค่าที่ใช้ประมวลจริงปรากฎในคอลัมน์ Runtime Value ด้วย
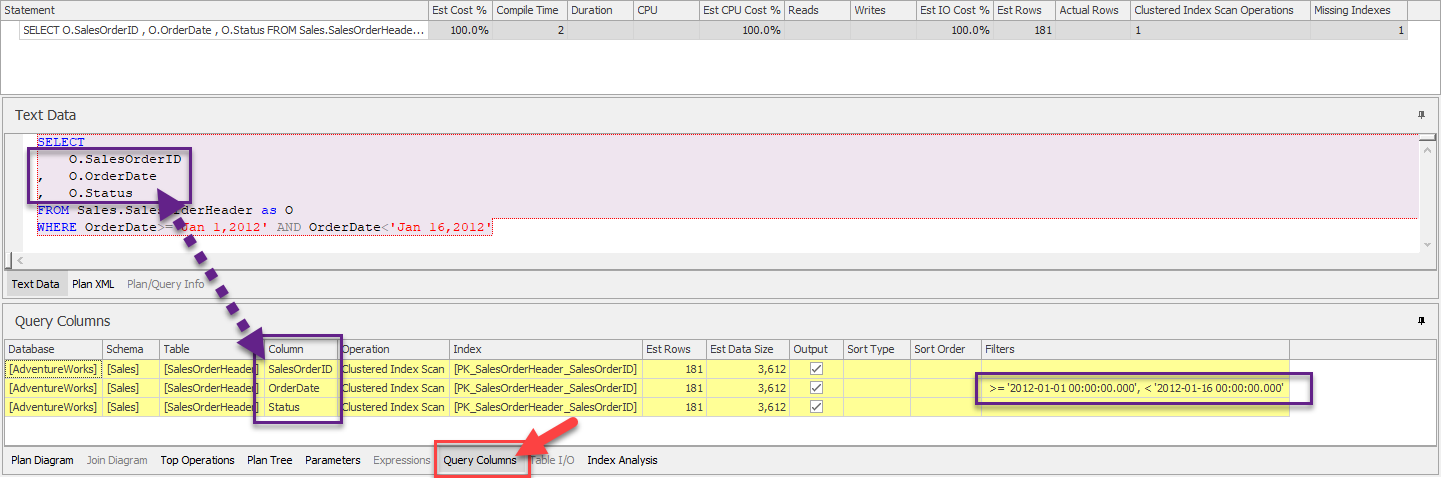
- แท็บถัดมาเป็นแท็บ Query Columns จะให้ข้อมูลคอลัมน์ที่จะปรากฎ (หรือคอลัมน์ที่อยู่หลังประโยค SELECT นั่นเอง)
หากคอลัมน์ไหนถูกกรองโดย Predicate หลังประโยค WHERE ด้วยก็จะเห็นรายละเอียดการกรองอยู่ในคอลัมน์ Filters ดังแสดง
- แท็บสุดท้ายที่จะแนะนำคือแท็บ Index Analysis ผู้เขียนขอใช้แท็บนี้ยกเป็นกรณีศึกษาในหัวข้อถัดไป
กรณีศึกษา: การสร้าง Index เพื่อเพิ่มประสิทธิภาพ Query ด้วย Plan Explorer
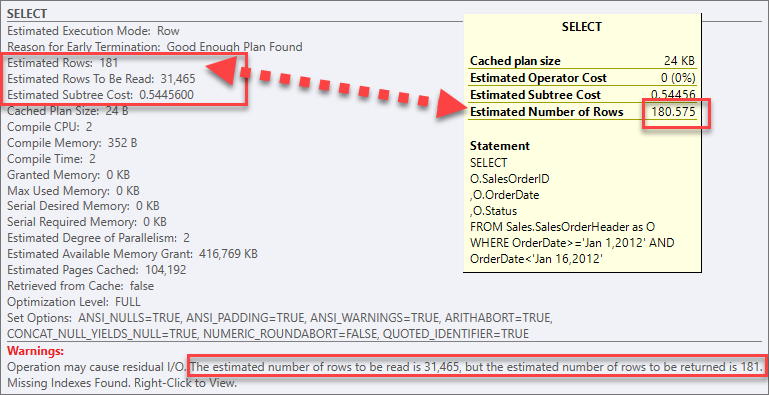
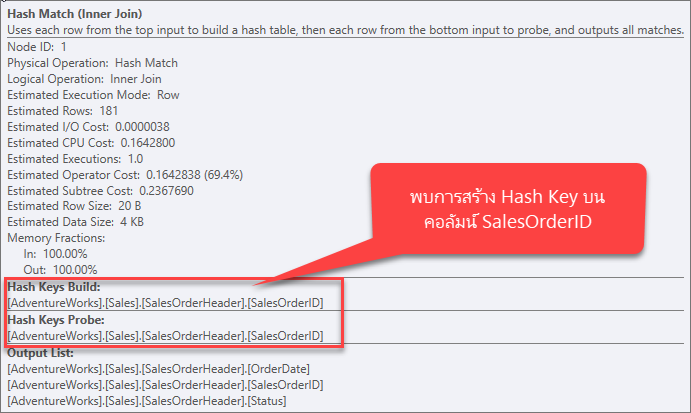
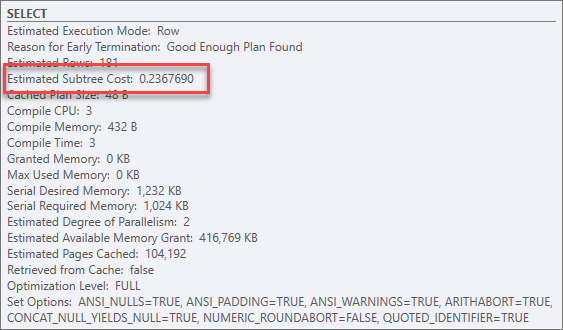
ข้อมูลจากตัวดำเนินการ SELECT พบว่า Estimated Subtree Cost ทั้งสิ้นเท่ากับ 0.54456
เราสามารถลด Cost ลงด้วยการปรับแต่ง Index รายละเอียดของแท็บ Index Analysis ที่พูดค้างเอาไว้ก่อนหน้ามีดังนี้
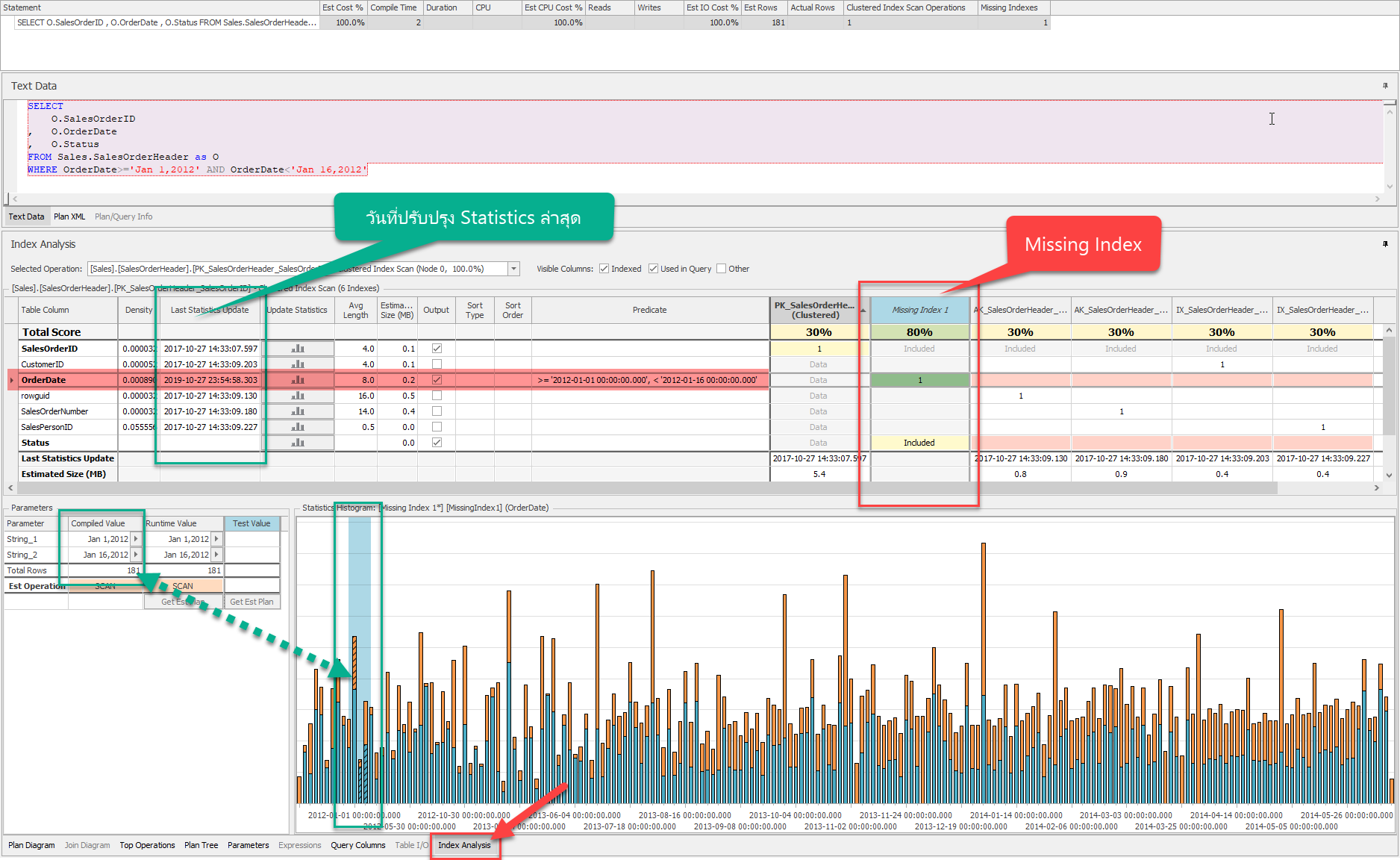
- Indexes ที่เกี่ยวข้องและมีโอกาสถูกนำมาใช้ภายใน Plan
- รายละเอียดของ Statistics
- ข้อมูลในรูปแบบของฮีสโตแกรม
- วันที่ปรับปรุง Statistics ล่าสุดเพื่อดูความเป็นปัจจุบัน
- พารามิเตอร์ที่เป็นตัวบอกว่า Cardinality Estimator จะหยิบฮีสโตแกรมแท่งไหนบ้างไปใช้ในการคำนวน
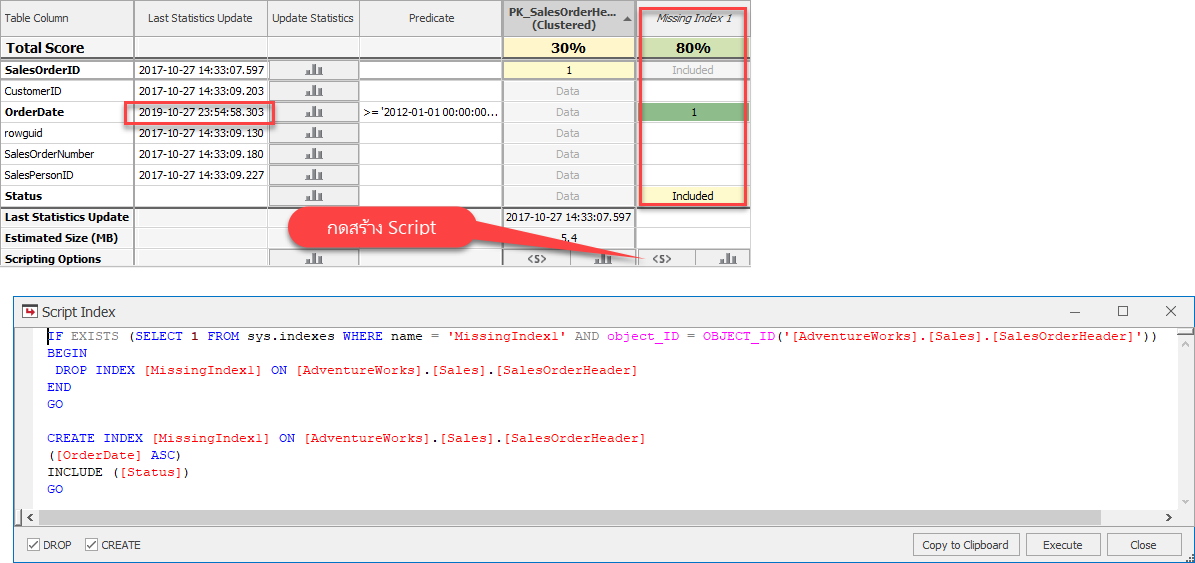
ผู้เขียนขอให้สังเกตว่ามีคอลัมน์ Missing Index ปรากฎอยู่ด้วย แสดงว่ายังไม่มี Index ตัวนี้อยู่
แต่ถ้ามีโอกาสที่ถูกเลือกใช้มากถึง 80% (ดูจาก Total Score)
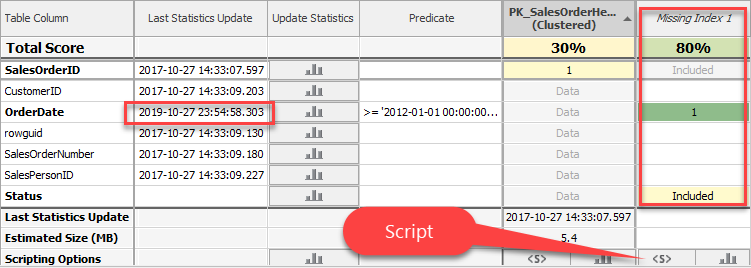
จากรูปข้างบนบอกอะไรเราได้บ้าง
- Missing Index ที่แนะนำเป็นชนิด Covering Index เป็นการสร้าง Index บนคอลัมน์เดียวคือ OrderDate (เลขแต่ละเลขหมายถึงลำดับคอลัมน์ใน Index ในรูปมีเพียงเลข 1 ดังนั้นจึงมีเพียงคอลัมน์เดียว) แต่จะเพิ่มคอลัมน์ Status ผ่านประโยค INCLUDE (Covering Index คือ Non-Clustered Index ที่มีการเติมคอลัมน์เพิ่มลงในระดับ Leaf ของโครงสร้าง Index ผ่านประโยค INCLUDE ประโยชน์เพื่อให้การประมวลผลสืบค้นจบที่ตัว Index เลยเพราะมีข้อมูลพร้อมสำหรับการแสดงผล)
- พบว่ามี Index ชื่อ PK_SalesOrderHeader_SalesOrderID เป็นชนิด Clustered Index แสดงว่าตาราง Sales.SalesOrderHeader มีโครงสร้างแบบ Clustered และมี SalesOrderID เป็น Clustered Key ข้อมูลในตาราง (ใน Physical Storage) จะมีการเรียงตามคอลัมน์ที่มีเลขระบุอยู่ในที่นี้คือ SalesOrderID (Clustered Key สามารถเป็น Composite จากหลายคอลัมน์ได้ และ Clustered Key ของตารางจะถูกใส่ลงในระดับ Leaf ของโครงสร้าง Non-Clustered Indexes ทุกตัวที่อยู่ในตารางนี้)
- มี Statistics บนคอลัมน์ OrderDate แม้ไม่มี Index ใดมีคอลัมน์ OrderDate เป็นองค์ประกอบเลยก็ตาม (ผู้เขียนรันสคริปต์เพื่อลบ Index ทุกตัวที่มี OrderDate เป็นองค์ประกอบไปก่อนหน้านี้แล้ว)
จากที่เคยเขียนในบทความหลายบทความก่อนหน้าไปแล้วว่า Statistics ถูกสร้างอัตโนมัติได้หลายกรณี
- กรณีที่สร้าง Index จะสร้าง Statistics ชื่อเดียวกันขึ้นมาอัตโนมัติ
- กรณีมีการใช้งานคอลัมน์ผ่านประโยค WHERE, GROUP BY หรือ ORDER BY โดยไม่มีคอลัมน์ดังกล่าวเป็นองค์ประกอบใน Index ตัวใดเลย ก็จะสร้าง Statistics ให้อัตโนมัติ โดยมีชื่อขึ้นต้นด้วย _WA_Sys
ผู้เขียนสืบค้นชื่อของ Statistics ผ่านสคริปต์ต่อไปนี้
SELECT S.name as StatisticsName FROM sys.stats as S INNER JOIN sys.stats_columns as SC ON S.object_id=SC.object_id AND S.stats_id=SC.stats_id INNER JOIN sys.columns as C ON SC.object_id=C.object_id AND SC.column_id=C.column_id WHERE C.name='OrderDate'; |
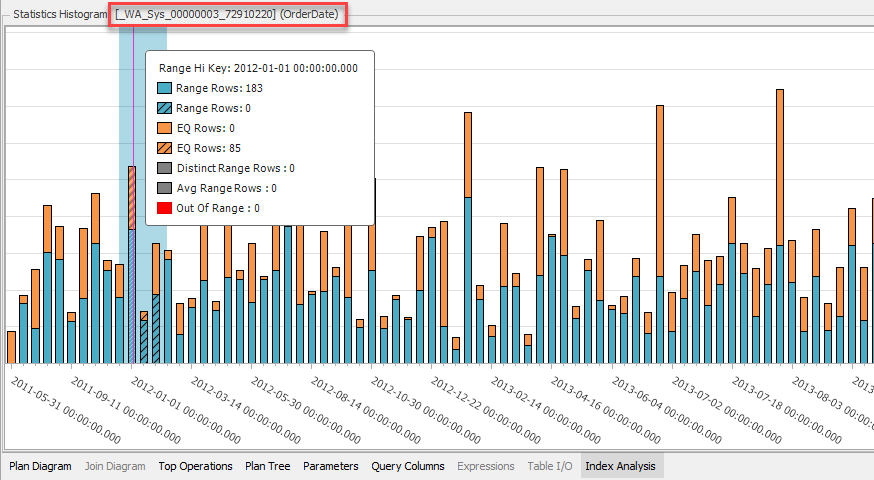
ได้ชื่อของ Statistics ออกมาเป็น _WA_Sys_00000003_72910220 ดังแสดง
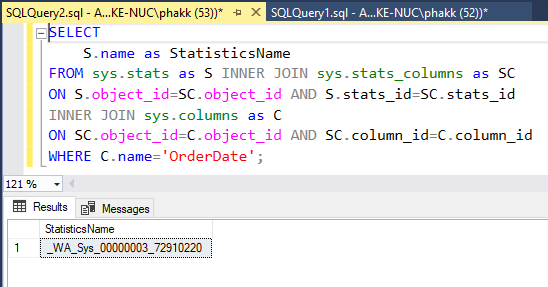
ผลลัพธ์อาจแตกต่างไปในแต่ละเครื่อง เพราะตัวข้างหลังเป็นการ Random ขึ้นมา
ผู้เขียนได้ลองดึงข้อมูลของ Statistics ดังกล่าวผ่าน SSMS ได้ข้อมูลดังนี้
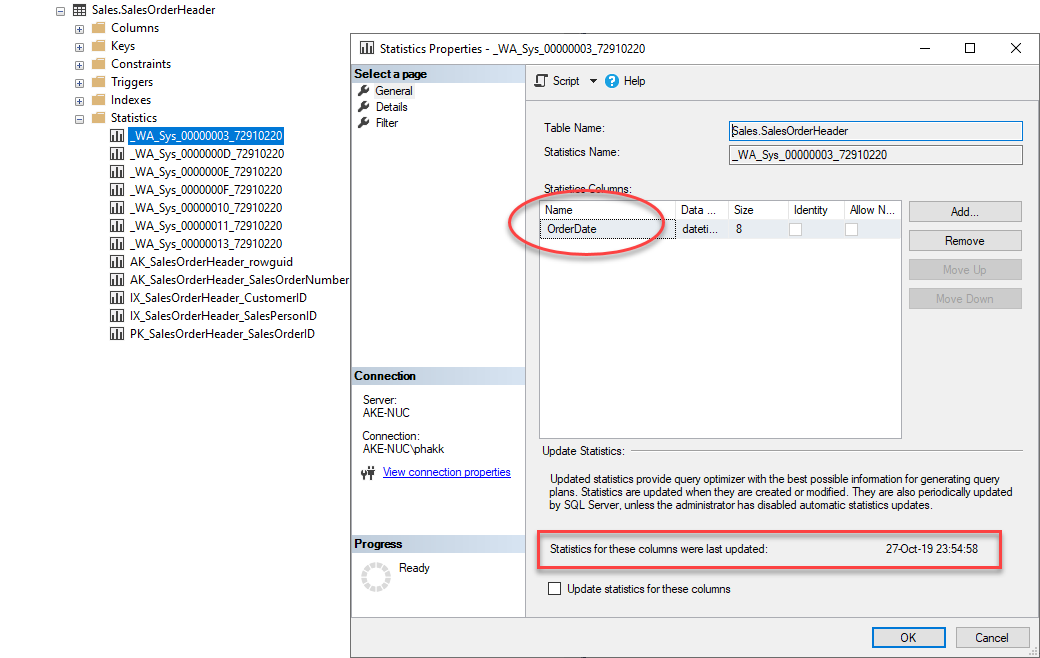
พบว่ามีคอลัมน์ OrderDate เป็นองค์ประกอบและปรับปรุงล่าสุดตรงกับที่แสดงผลในแท็บ Index Analysis ของ SentryOne Plan Explorer เราสามารถเรียกดูค่าฮิสโตแกรมของ Statistics ผ่านคำสั่ง DBCC SHOWSTATISTICS ได้ดังนี้
DBCC SHOW_STATISTICS ( 'Sales.SalesOrderHeader' , '_WA_Sys_00000003_72910220' ) WITH HISTOGRAM; |
ผลลัพธ์ที่ได้ดังแสดง
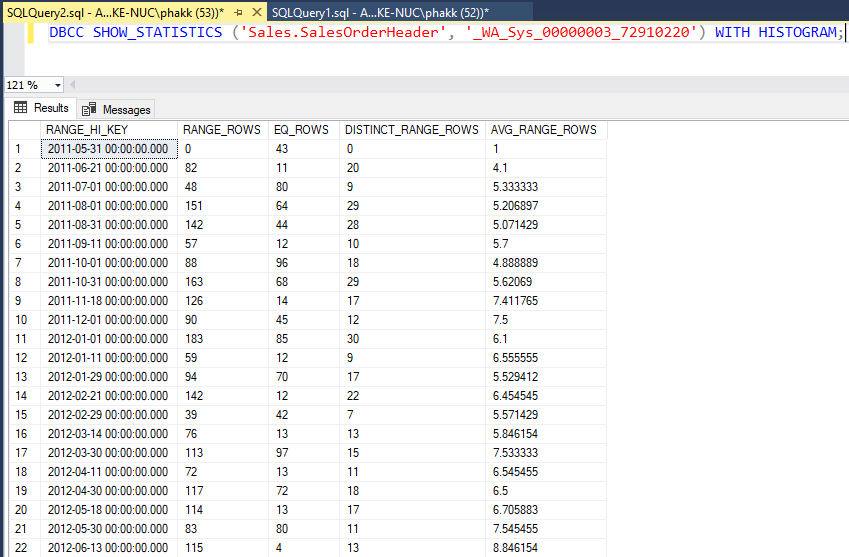
แต่การแสดงผลบน SentryOne Plan Explorer ดีกว่ามาก เพราะแสดงฮีสโตแกรมเป็นแผนภูมิจริงๆ เลยดังแสดง
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate ON Sales.SalesOrderHeader ( OrderDate ASC ); |
หลังจากสร้าง Index เสร็จแล้วให้กดปุ่ม Get Estimated Plan ใน SentryOne Plan Explorer อีกครั้ง จะพบว่ามีการเลือก Compiled Plan ใหม่มาแทน Plan เดิม ดังแสดง

และมีการใช้งาน Index ตัวที่สร้างขึ้น และภาระงานไปตกที่ตัวดำเนินการ Key Lookup
ในที่นี้คือคอลัมน์ SalesOrderID ไปเติมไว้ในระดับ Leaf ของทุกๆ Non-Clustered Index
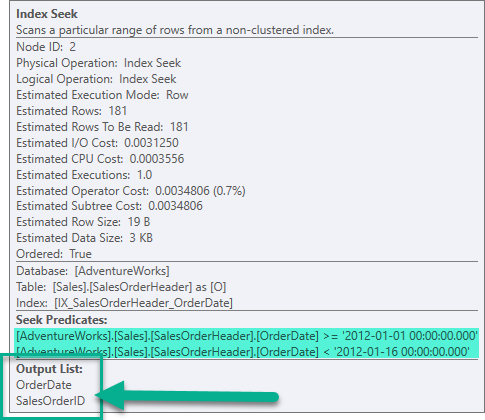
ผลลัพธ์ที่ได้คือช่วงข้อมูลใน OrderDate ต้องการ พร้อมกับ SalesOrderID (Clustered Key ที่ถูกเติมเข้ามา) ผนวกมาด้วย
คำสั่ง SELECT ของเราต้องการแสดงผลคอลัมน์ SalesOrderID, OrderDate และ Status
โดย SalesOrderID และ OrderDate พบแล้วใน Index
ขาดแต่คอลัมน์ Status ที่ต้องนำเอา SalesOrderID ไป Lookup มา
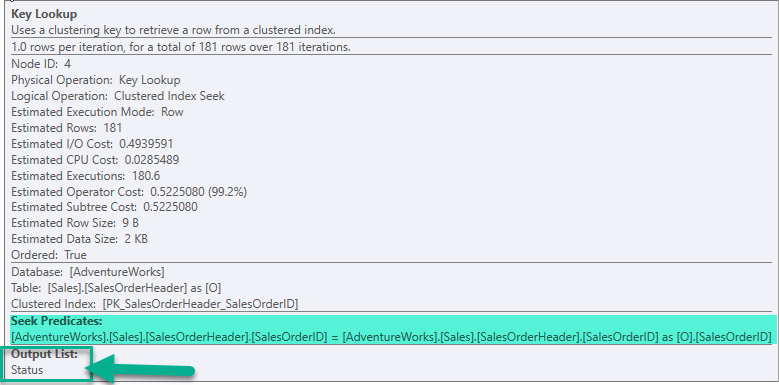
จากรูปจะเห็นว่า Seek Predicates เป็นการนำ SalesOrderID ไป Lookup ที่ตาราง Sales.SalesOrderHeader
ผลลัพธ์ที่ได้คือคอลัมน์ Status ของแต่ละ SalesOrderID
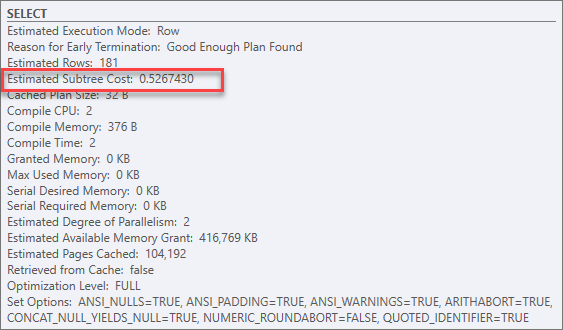
พบว่า Cost ลดลงจาก 0.54456 เป็น 0.526743 ซึ่งลดลงไม่มาก
ผู้เขียนยังคงหาหนทางลด Cost ลงไปอีกโดยลองสร้าง Non-Clustered Index เพิ่มอีก โดยมีเพียงคอลัมน์ Status เป็นองค์ประกอบ ด้วยคำสั่งต่อไปนี้
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_Status ON Sales.SalesOrderHeader ( Status ASC ); |
หลังจากสร้าง Index เสร็จแล้วให้กดปุ่ม Get Estimated Plan ใน SentryOne Plan Explorer อีกครั้ง จะพบว่ามีการเลือก Compiled Plan ใหม่มาแทน Plan เดิม ดังแสดง
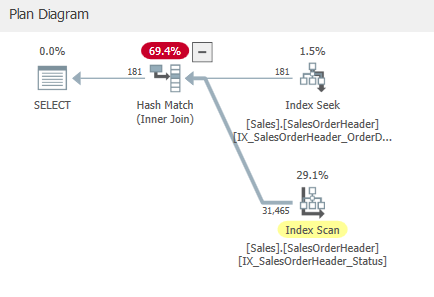
พบว่าตัวดำเนินการจับคู่ข้อมูลจากสองอินพุตเปลี่ยนเป็น Hash Match Join และมีภาระงานสูงสุดใน Plan
เพราะข้อมูลในการเข้าจับคู่ไม่เรียงอยู่ ทำให้ต้องสร้าง Hash Key ขึ้นมาจับคู่แทน
- • อินพุตที่ 1 Index Seek บน IX_SalesOrderHeader_OrderDate
- ข้อมูลเรียงตาม OrderDate
- ข้อมูล SalesOrderID อาจเรียงหรือไม่เรียงอยู่
- อินพุตที่ 2 Index Scan บน IX_SalesOrderHeader_Status
- ข้อมูลเรียงตาม Status
- ข้อมูล SalesOrderID กระจายตามการเรียงของ Status ทำให้ SalesOrderID ไม่เรียงอยู่
พบว่า Cost ลดลงไปพอสมควรจาก 0.54456 เป็น 0.236769 ซึ่งลดลงเกินครึ่งไปนิดหน่อย
ผู้เขียนทำการลบ Indexes ทั้งสองทิ้งไปด้วยคำสั่งต่อไปนี้
DROP INDEX IX_SalesOrderHeader_OrderDate ON Sales.SalesOrderHeader; DROP INDEX IX_SalesOrderHeader_Status ON Sales.SalesOrderHeader; |
ให้กดปุ่ม Get Estimated Plan ใน SentryOne Plan Explorer อีกครั้ง
จะพบว่า Compiled Plan ที่ถูกเลือกเข้ามา มีรายละเอียดเหมือนก่อนการทดลองแรก
สคริปต์ดังกล่าวเป็นการสร้าง Covering Index โดยเติมคอลัมน์ Status ลงในระดับ Leaf ของโครงสร้าง Index ทำให้ Index ตัวนี้ประกอบด้วยคอลัมน์
- OrderDate เป็นข้อมูลที่เรียงอยู่ในโครงสร้าง B+ Tree ตั้งแต่ระดับ Root, Intermediate และ Leaf
- SalesOrderID เป็น Clustered Key ที่ถูกเติมเข้ามาในระดับ Leaf
- Status ถูกเติมเข้ามาในระดับ Leaf ผ่านประโยค INCLUDE
CREATE INDEX IX_SalesOrderHeader_OrderDate_INC_Status ON Sales.SalesOrderHeader ( OrderDate ASC ) INCLUDE (Status); |
หลังจากสร้าง Index เสร็จแล้วให้กดปุ่ม Get Estimated Plan ใน SentryOne Plan Explorer อีกครั้ง
จะพบว่ามีการเลือก Compiled Plan ใหม่มาแทน Plan เดิม ดังแสดง

เมื่อท่องไปใน Tree ตาม Seek Predicates (คอลัมน์ OrderDate ใน Index) จนได้ช่วงข้อมูลออกมาก็จะได้ค่าของคอลัมน์ SalesOrderID
และ Status ที่ถูกบรรจุไว้ในระดับ Leaf ออกมาด้วย ทำให้การสืบค้นจบลงที่ตัว Index เลย ไม่ต้องไป Lookup ต่อในตารางอีก
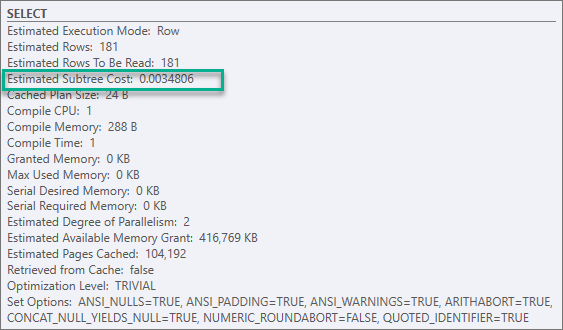
Subtree Cost ของตัวดำเนินการนี้จึงเป็นของทั้ง Plan ด้วย ซึ่งเท่ากับ 0.0034806
จากเดิม 0.54456 ถือว่าประสิทธิภาพสูงขึ้นมาก
ก็สามารถดูข้อมูลของตัวดำเนินการ SELECT ได้
สรุป
ตัวอย่างการสร้าง Index ทั้งสองแบบ เป็นเพียงการทดลองให้เห็นความแตกต่าง
ผู้เขียนไม่อยากชี้นำว่าเมื่อมีตัวดำเนินการ Lookup เกิดขึ้น จะต้องแก้ด้วย Covering Index ตลอด
เพราะ Covering Index ก็เป็น Non-Clustered Index แบบหนึ่ง มีได้และช่วยให้คิวรี่ได้เร็วขึ้นก็จริง
แต่มีเยอะเป็นภาระของ Storage และทำให้ Insert, Update และ Delete ข้อมูลในตารางช้าลง
ผู้อ่านควรหาจุดสมดุลย์ด้วยตัวเอง