
ทักษะ (ระบุได้หลายทักษะ)
เก่งโค้ดงาน Business Intelligence ตอนที่ 3
การอ้างแบบจำเพาะ
ในภาษาเอ็มเราสามารถอ้างอิงถึงตัวแปรหรือสิ่งต่าง ๆ ที่อยู่ภายในสภาพแวดล้อมได้โดยใช้ “ตัวระบุ”
หลักการนี้มีชื่อว่า “การอ้างด้วยตัวระบุ” (Identifier References IR) ซึ่งมีสองแบบคือ
หลักการนี้มีชื่อว่า “การอ้างด้วยตัวระบุ” (Identifier References IR) ซึ่งมีสองแบบคือ
- “การอ้างด้วยตัวระบุจำเพาะ” (Exclusive-identifier-reference EIR) ที่เป็นวิธีปรกติ
- “การอ้างด้วยตัวระบุไม่จำเพาะ” (Inclusive-identifier-reference IIR) ซึ่งเป็นวิธีพิเศษ
การอ้างด้วยวิธี EIR ต่อตัวแปร (หรือสิ่งอื่นใด) ที่อยู่นอกสภาพแวดล้อม หรือต่อตัวแปรที่กำลังถูกสร้างทำไม่ได้ และจะเกิด Error
ในกรณีนี้จำเป็นต้องใช้วิธี IIR แทน แต่ถ้าท่านใช้วิธีแบบ IIR ในสถานะการณ์ปรกติก็จะไม่มีผลอะไรและการทำงานก็จะเหมือน EIR
ในกรณีนี้จำเป็นต้องใช้วิธี IIR แทน แต่ถ้าท่านใช้วิธีแบบ IIR ในสถานะการณ์ปรกติก็จะไม่มีผลอะไรและการทำงานก็จะเหมือน EIR
การอ้างถึงตัวแปรด้วยวิธี IIR ทำได้โดยใส่เครื่องหมาย @ ไว้นำหน้าตัวแปรที่ต้องการ ซึ่งจะมีประโยชน์ในกรณีที่ต้องการอ้างถึงฟังก์ชันในตัวฟังก์ชันเอง (การทำรีเคอร์ซีฟ) เพราะโค้ดที่เป็นไส้ของฟังก์ชันย่อมอยู่นอกสภาพแวดล้อมของฟังก์ชันนั้นเนื่องจากเป็นบริเวณที่ฟังก์ชันนั้นกำลังถูกสร้าง

รูปที่ 1
บรรทัด 5 คือ Systax ของการอ้างแบบ EIR
บรรทัด 8 คือซินแท็กของการอ้างแบบ IIR
บรรทัด 5 คือ Systax ของการอ้างแบบ EIR
บรรทัด 8 คือซินแท็กของการอ้างแบบ IIR
บรรทัดที่ 10-18 คือนิยามฟังก์ชัน Factorial ที่เป็นรีเคอร์ซีฟฟังก์ชัน
โค้ดที่อยู่ภายในฟังก์ชันนี้ต้องการอ้างถึงฟังก์ชันนี้ (บรรทัด 15) จึงจำเป็นต้องอ้างแบบ EIR
ในขณะที่โค้ดบรรทัด 18 เป็นโค้ดที่อยู่นอกนิยามฟังก์ชัน ต้องการอ้างถึงฟังก์ชัน จะสามารถอ้างโดยใช้วิธี IIR ได้ตามปรกติ
โค้ดที่อยู่ภายในฟังก์ชันนี้ต้องการอ้างถึงฟังก์ชันนี้ (บรรทัด 15) จึงจำเป็นต้องอ้างแบบ EIR
ในขณะที่โค้ดบรรทัด 18 เป็นโค้ดที่อยู่นอกนิยามฟังก์ชัน ต้องการอ้างถึงฟังก์ชัน จะสามารถอ้างโดยใช้วิธี IIR ได้ตามปรกติ
สร้างฟังก์ชันลบอักษรออกจากข้อมูลตัวเลข
บ่อยครั้งที่ข้อมูลที่ถูกนำเข้ามา มีตัวอักษรบนอยู่กับตัวเลข ทำให้ไม่สามารถนำข้อมูลไปประมวลผลได้ ในหัวข้อนี้แสดงวิธีนิยามฟังก์ชันเพื่อลบตัวอักษรที่ปะปนอยู่ในตารางข้อมูลตัวเลข
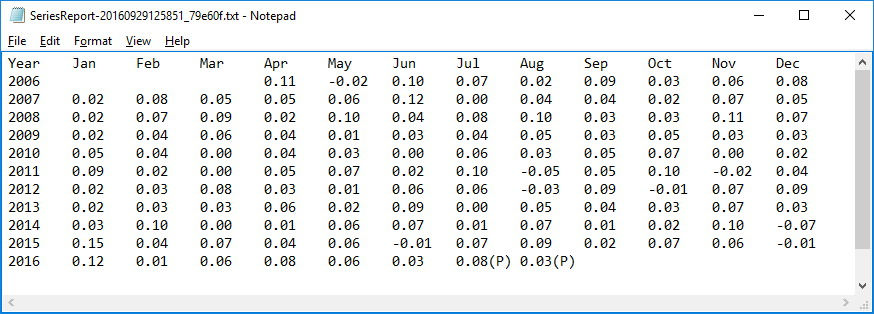
รูปที่ 2 คือแฟ้มข้อมูลตัวอักษรธรรมดาที่เราจะนำเข้าไปในโปรแกรมเอ็กเซล
เป็นตารางข้อมูลแสดงความเปลี่ยนแปลงของค่าจ้างแรงงานภาคเอกชนในแต่ละเดือนระหว่างปี 2006 ถึงปี 2016
ปัญหา คือ ข้อมูลที่ควรจะเป็นตัวเลขทั้งหมด ปรากฏว่ามี (P) ปนมาด้วย
เพราะเป็นข้อมูลที่ถูกนำออกจากกระดาษงานที่บางเซลใส่คำอธิบายไว้ (ใส่ annotation)
เมื่อถูกเอ็กซ์พอร์ทอันโนเตชันจะกลายเป็นข้อความ (P) ต่อท้ายข้อมูล
เป็นตารางข้อมูลแสดงความเปลี่ยนแปลงของค่าจ้างแรงงานภาคเอกชนในแต่ละเดือนระหว่างปี 2006 ถึงปี 2016
ปัญหา คือ ข้อมูลที่ควรจะเป็นตัวเลขทั้งหมด ปรากฏว่ามี (P) ปนมาด้วย
เพราะเป็นข้อมูลที่ถูกนำออกจากกระดาษงานที่บางเซลใส่คำอธิบายไว้ (ใส่ annotation)
เมื่อถูกเอ็กซ์พอร์ทอันโนเตชันจะกลายเป็นข้อความ (P) ต่อท้ายข้อมูล
การแก้ปัญหาทำได้ง่ายในเอ็กเซลโดยการมองหาเซลที่มี (P) ปนมาแล้วลบออกด้วยมือ
แต่ในกรณีที่ต้องนำเข้าข้อมูลบ่อย ๆ และตำแหน่งที่มี (P) ปนมาไม่แน่นอน
การทำด้วยมือจะเป็นภาระมาก วิธีที่ดีกว่า คือ ทำให้ทุกอย่างการเป็นอัตโนมัติซึ่งทำได้โดยการเขียนฟังก์ชันในภาษา M
แต่ในกรณีที่ต้องนำเข้าข้อมูลบ่อย ๆ และตำแหน่งที่มี (P) ปนมาไม่แน่นอน
การทำด้วยมือจะเป็นภาระมาก วิธีที่ดีกว่า คือ ทำให้ทุกอย่างการเป็นอัตโนมัติซึ่งทำได้โดยการเขียนฟังก์ชันในภาษา M
กระบวนการที่เราจะจัดการต่อปัญหานี้มีสามขั้นตอนคือ
- นำเข้าข้อมูล คอลัมน์ทั้งหมดจะมีชนิดข้อมูลเป็นตัวเลขทศนิยม ยกเว้นคอลัมน์ที่มีตัวอักษรปน
- แปลงข้อมูลทั้งหมดเป็นอาร์เรย์ตัวอักษรเพื่อให้สามารถใช้เมธอด Table.ReplaceValue ได้
- แทนค่า (P) ที่ปนมาด้วยข้อความเปล่า สุดท้ายคือแปลงข้อมูลทั้งหมดให้กลับเป็นตัวเลขทศนิยม

รูปที่ 3 คือโค้ดภาษา M ที่ทำกระบวนการสามขั้นตอนดังกล่าว
- บรรทัดที่ 4 นำเข้าแฟ้มข้อมูลตัวอักษร
- บรรทัดที่ 6 ใส่ชื่อคอลัมน์
- บรรทัดที่ 8 แปลงชนิดข้อมูลจากแบบตัวเลขมีทศนิยมให้กลายเป็นตัวอักษร
- บรรทัดที่ 10 แทนคำว่า (P) ด้วย “” (สตริงก์ว่าง) โดยใช้เมธอด Table.ReplaceValue
- บรรทัดที่ 12 แปลงชนิดข้อมูลจากตัวอักษรกลับมาเป็นตัวเลขตามเดิม
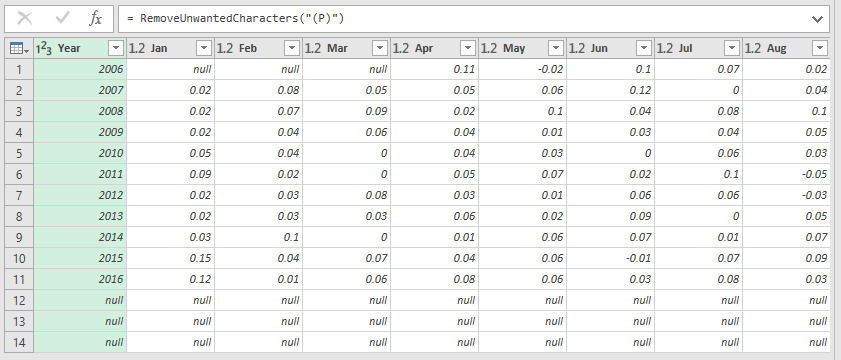
ถ้าจะเอาโค้ดในรูปที่ 3 ไปใช้งานก็ได้ แต่ไม่สะดวก เพราะถ้าตัวอักษรที่ปนมากับตัวเลขไม่ใช่ (P) โค้ดนี้ก็แก้ปัญหาไม่ได้
วิธีที่ดีกว่าคือแปลงโค้ดนี้ให้เป็นฟังก์ชันที่มีพารามิเตอร์เป็นตัวอักษรที่ต้องการลบออก

รูปที่ 4 คือ ฟังก์ชันดังกล่าว
โปรดสังเกตว่าโค้ดเหมือนรูปที่ 3 เกือบทุกอย่าง
เพิ่มบรรทัด 4 เพื่อรับอินพุตพารามิเตอร์
แล้วแก้ไขบรรทัด 12 จากเดิมเป็น (P) ให้กลายเป็นอินพุตพารามิเตอร์ คือ unwanted Characters
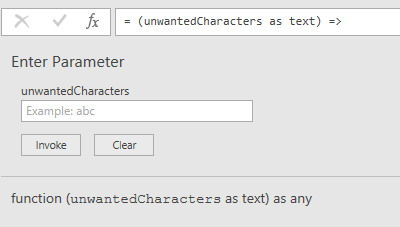
รูปที่ 5
เมื่อเรียกใช้งานฟังก์ชันนี้จะปรากฏกรอบข้อความอย่างที่เห็นในรูปที่ 5
เพื่อแจ้งเตือนให้เราป้อนพิมพ์ตัวอักษรที่ต้องการจะให้ลบออก
ข้อจำกัดของฟังก์ชันนี้ คือ หากเราป้อนตัวอักษรไม่ตรงกับตัวอักษรที่ปนอยู่จะเกิด Error
ในกรณีนี้หากเราป้อนดี คือป้อนว่า (P) ผลลัพธ์จะเป็นอย่างที่เห็นในรูปที่ 6

รูปที่ 6
ลำดับการประเมินค่า
ตัวแปลภาษาของภาษา M อาจจัดลำดับการประเมินค่าโดยไม่ไล่ตามบรรทัดก่อนหลัง
ยกตัวอย่างเช่น
ลองพิจารณาโค้ดบรรทัดที่ 4-8 ในรูปที่ 7 ซึ่งทำหน้าที่สร้างเรคคอร์ดที่มีสามฟิลด์คือ A, B และ C เมื่อโค้ดนี้ทำงานเราจะได้เรคคอร์ดที่มีค่าอย่างที่เห็นในบรรทัดที่ 10-14
เนื่องจากบรรทัดที่ 5 ไม่สามารถจะถูกประเมินค่าได้ก่อนบรรทัดที่ 6 และ 7 เพราะฟิลด์ C มาค่าจากฟิลด์ A และ B เราเรียกสภาพการแบบนี้ว่า “การผูกพันโดยลำดับ” (dependency ordering)
ดังนั้นตัวแปลภาษาต้องทำงานตามลำดับอย่างที่เห็นในบรรทัด 16-18
คือต้องหาค่าของ A และ B ก่อนจึงจะหาค่า B ได้ หรือตัวแปลภาษาอาจทำงานในลำดับแบบบรรทัดที่ 20-22 ก็ได้
และเนื่องจากบรรทัด 20 กับ 21 ไม่ผูกพันกันโดยลำดับการทำงาน
ดังนั้นตัวแปลภาษาเอ็มอาจทำบรรทัด 20 และ 21 ไปพร้อม ๆ กันเลยก็ได้ (ทำงานคู่ขนาน)
ยกตัวอย่างเช่น
ลองพิจารณาโค้ดบรรทัดที่ 4-8 ในรูปที่ 7 ซึ่งทำหน้าที่สร้างเรคคอร์ดที่มีสามฟิลด์คือ A, B และ C เมื่อโค้ดนี้ทำงานเราจะได้เรคคอร์ดที่มีค่าอย่างที่เห็นในบรรทัดที่ 10-14
เนื่องจากบรรทัดที่ 5 ไม่สามารถจะถูกประเมินค่าได้ก่อนบรรทัดที่ 6 และ 7 เพราะฟิลด์ C มาค่าจากฟิลด์ A และ B เราเรียกสภาพการแบบนี้ว่า “การผูกพันโดยลำดับ” (dependency ordering)
ดังนั้นตัวแปลภาษาต้องทำงานตามลำดับอย่างที่เห็นในบรรทัด 16-18
คือต้องหาค่าของ A และ B ก่อนจึงจะหาค่า B ได้ หรือตัวแปลภาษาอาจทำงานในลำดับแบบบรรทัดที่ 20-22 ก็ได้
และเนื่องจากบรรทัด 20 กับ 21 ไม่ผูกพันกันโดยลำดับการทำงาน
ดังนั้นตัวแปลภาษาเอ็มอาจทำบรรทัด 20 และ 21 ไปพร้อม ๆ กันเลยก็ได้ (ทำงานคู่ขนาน)

รูปที่ 7
เรคคอร์ดและฟิลด์
เรคคอร์ด คือ โครงสร้างข้อมูลที่ประกอบด้วยรายการฟิลด์
คำว่าฟิลด์ในที่นี้คล้าย ๆ ตัวแปร คือ ประกอบด้วยชื่อและค่าที่ฟิลด์เก็บไว้
บรรทัด 4 คือเรคอร์ดในลักษณะสามัญสุดประกอบด้วยฟิลด์สองฟิลด์คือ x ที่มีค่า 1 และ y ที่มีค่า 2 เราอาจนิยามเรคคอร์ดซ้อนเรคคอร์ดได้ นั่นคือนอกจากค่าของฟิลด์จะเป็นข้อมูลตัวเลขหรืออื่น ๆ แล้ว สมาชิกของเรคคอร์ดอาจจะเป็นเรคคอร์ดได้ด้วย
บรรทัด 6 คือเรคคอร์ดที่มีฟิลด์ a และค่าของฟิลด์ a คือเรคคอร์ด ชื่อฟิลด์ภายในเรคคอร์ดจะซ้ำกันไม่ได้
บรรทัด 8 จะ Error เพราะมีชื่อฟิลด์ซ้ำกันขณะที่บรรทัด 9 ไม่มีปัญหา ถ้าเรคคอร์ดไม่มีฟิลด์อยู่เลยจะเรียกว่า “เรคคอร์ดว่าง”
บรรทัด 11 คือวิธีเขียนเรคคอร์ดว่าง ลำดับของรายการฟิลด์ภายในเรคคอร์ดไม่สร้างความแตกต่าง เมื่อนำสองเรคอร์ดมาเปรียบเทียบกัน หรือเมื่อเข้าถึงค่าของฟิลด์ แต่จะสร้างความแตกต่างเมื่อเข้าถึงตัวฟิลด์เอง
ยกตัวอย่าเช่น
โค้ดบรรทัด 13, 14 เรียกใช้ฟังก์ชัน Record.FieldNames ที่เข้าถึงตัวฟิลด์ (ไม่ใช่ค่าของฟิลด์) เพื่ออ่านชื่อฟิลด์ โค้ดสองบรรทัดนี้จะให้ผลลัพธ์ต่างกัน
คำว่าฟิลด์ในที่นี้คล้าย ๆ ตัวแปร คือ ประกอบด้วยชื่อและค่าที่ฟิลด์เก็บไว้
บรรทัด 4 คือเรคอร์ดในลักษณะสามัญสุดประกอบด้วยฟิลด์สองฟิลด์คือ x ที่มีค่า 1 และ y ที่มีค่า 2 เราอาจนิยามเรคคอร์ดซ้อนเรคคอร์ดได้ นั่นคือนอกจากค่าของฟิลด์จะเป็นข้อมูลตัวเลขหรืออื่น ๆ แล้ว สมาชิกของเรคคอร์ดอาจจะเป็นเรคคอร์ดได้ด้วย
บรรทัด 6 คือเรคคอร์ดที่มีฟิลด์ a และค่าของฟิลด์ a คือเรคคอร์ด ชื่อฟิลด์ภายในเรคคอร์ดจะซ้ำกันไม่ได้
บรรทัด 8 จะ Error เพราะมีชื่อฟิลด์ซ้ำกันขณะที่บรรทัด 9 ไม่มีปัญหา ถ้าเรคคอร์ดไม่มีฟิลด์อยู่เลยจะเรียกว่า “เรคคอร์ดว่าง”
บรรทัด 11 คือวิธีเขียนเรคคอร์ดว่าง ลำดับของรายการฟิลด์ภายในเรคคอร์ดไม่สร้างความแตกต่าง เมื่อนำสองเรคอร์ดมาเปรียบเทียบกัน หรือเมื่อเข้าถึงค่าของฟิลด์ แต่จะสร้างความแตกต่างเมื่อเข้าถึงตัวฟิลด์เอง
ยกตัวอย่าเช่น
โค้ดบรรทัด 13, 14 เรียกใช้ฟังก์ชัน Record.FieldNames ที่เข้าถึงตัวฟิลด์ (ไม่ใช่ค่าของฟิลด์) เพื่ออ่านชื่อฟิลด์ โค้ดสองบรรทัดนี้จะให้ผลลัพธ์ต่างกัน
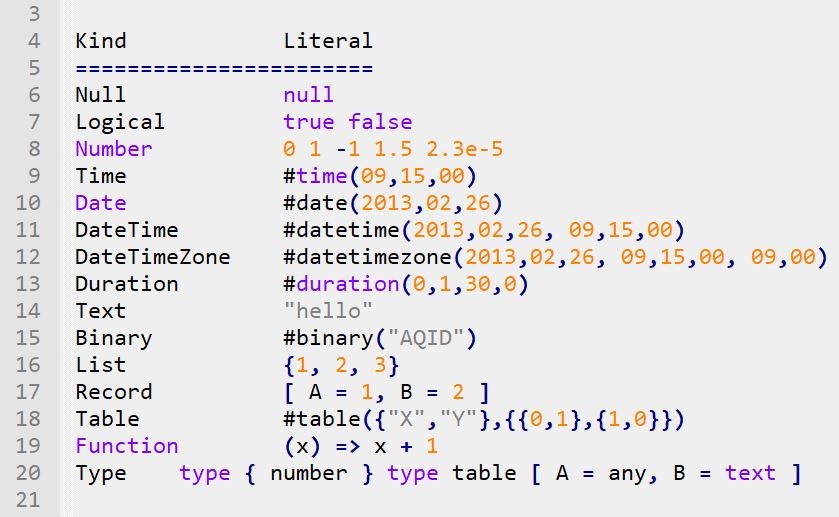
ชนิดข้อมูลในภาษาเอ็ม
รูปที่ 9 เป็นตารางแสดงชนิดข้อมูลทั้งหมดในภาษา M
- ค่า null ใช้แสดงความไม่มีข้อมูล
- ค่า Logical คือ ชนิดข้อมูลแบบ Boolean
- ค่า Number ใช้แสดงตัวเลขทุกแบบทั้งจำนวนเต็มและแบบมีทศนิยม
- ข้อมูลแบบ Time แสดงในรูปแบบ #time(hour, minute, second) ส่วน Date แสดงแบบ #date(year, month, day)
- ข้อมูลแบบ DateTime แสดงในรูปแบบ #datetime(year, month, day, hour, minute, second)
- ส่วน DateTimeZone เหมือน DateTime แต่เพิ่มค่าออพเซ็ตจาก Universal Coordinated Time (UTC) สองค่าคือ
- offset-hours และ
- offset-minutes
- ข้อมูลแบบ Duration เก็บความนาน ยกตัวอย่างเช่น #duration(0, 0, 0, 5.5) เท่ากับ 5.5 วินาที และ #duration(0, 24, 0, 0) เท่ากับหนึ่งวัน
- ข้อมูลแบบ Text เก็บตัวอักษรหนึ่งตัวหรือมากกว่า Binary เก็บรายการของไบต์ เช่น #binary( {0x00, 0x01, 0x02, 0x03} ) List, Record และ Table เป็นโครงสร้างข้อมูล Function เป็นการนิยามฟังก์ชันแบบแลมดา
- สุดท้าย คือ Type ใช้เพื่อกำหนดค่าให้แก่ค่าต่าง ๆ (ดูหัวข้อถัดไป)

ชนิดข้อมูลแบบ Type
ค่า Type ทำหน้าที่จัดกลุ่มค่าอื่น ๆ เช่น
- Primitive type(ค่าแบบพื้นฐาน)
- Record
- Table
- List
- Function และ
- ค่า Null
การเขียนโค้ดโดยอ้างถึง Type เหล่านี้ให้ใช้คำเฉพาะหรือคำสงวนดังต่อไปนี้
[any binary date datetime datetimezone duration function list logical none null number record table text time type]
เมื่ออ้างถึง Type ในบรรทัดคำสั่งType เองต้องใส่วงเล็บ
ยกตัวอย่างรูปที่ 10
บรรทัด 4 ต้องการอ้าง Type number ในบรรทัดคำสั่งที่เริ่มด้วย type ต้องใส่วงเล็บครอบ (วงเล็บหน้าฟังก์ชัน Type.ForList)
แต่ถ้าอ้างถึงชื่อ Type ไม่ต้องใส่วงเล็บ (ดูบรรทัด 5)
ในกรณีที่ชื่อตัวแปรซ้ำกับชื่อ type ให้ใส่วงเล็บที่ type
ยกตัวอย่างเช่น
บรรทัด 7 ตัวแปรชื่อ Record ซึ่งตรงกับชื่อ Type และในบรรทัดนี้อ้างถึง Type Record
ยกตัวอย่างรูปที่ 10
บรรทัด 4 ต้องการอ้าง Type number ในบรรทัดคำสั่งที่เริ่มด้วย type ต้องใส่วงเล็บครอบ (วงเล็บหน้าฟังก์ชัน Type.ForList)
แต่ถ้าอ้างถึงชื่อ Type ไม่ต้องใส่วงเล็บ (ดูบรรทัด 5)
ในกรณีที่ชื่อตัวแปรซ้ำกับชื่อ type ให้ใส่วงเล็บที่ type
ยกตัวอย่างเช่น
บรรทัด 7 ตัวแปรชื่อ Record ซึ่งตรงกับชื่อ Type และในบรรทัดนี้อ้างถึง Type Record
การนิยาม Type List ให้ใส่วงเล็บปีกกา (ดูบรรทัด 10) การนิยามเรคคอร์ดให้ใส่วงเล็บก้ามปู [ ] (ดูบรรทัด 11)
การหา Type ของค่าทำได้โดยใช้ฟังก์ชัน Value.Type ที่อยู่ใน Libraly มาตรฐาน (ดูบรรทัด 14-16)
เราอาจใช้ตัวกระทำ is เพื่อตรวจสอบว่าค่าของ Type ตรงกับค่าใด ๆ หรือไม่ (ดูบรรทัด 18-20)
ผลลัพธ์ได้เป็นค่า Boolean
ตัวกระทำ as ใช้เพื่อตรวจสอบว่าค่าของ Type ตรงกับค่าใด ๆ หรือไม่ (ดูบรรทัด 22)
ผลลัพธ์ ถ้าตรงได้เป็นค่าเดิม ถ้าไม่ตรงได้เป็น Error
การหา Type ของค่าทำได้โดยใช้ฟังก์ชัน Value.Type ที่อยู่ใน Libraly มาตรฐาน (ดูบรรทัด 14-16)
เราอาจใช้ตัวกระทำ is เพื่อตรวจสอบว่าค่าของ Type ตรงกับค่าใด ๆ หรือไม่ (ดูบรรทัด 18-20)
ผลลัพธ์ได้เป็นค่า Boolean
ตัวกระทำ as ใช้เพื่อตรวจสอบว่าค่าของ Type ตรงกับค่าใด ๆ หรือไม่ (ดูบรรทัด 22)
ผลลัพธ์ ถ้าตรงได้เป็นค่าเดิม ถ้าไม่ตรงได้เป็น Error

การอ้างถึงหน่วยในรายการ
การอ้างถึงหน่วยหรือสมาชิกในโครงสร้างข้อมูลให้อ้างด้วยดรรชนี
โดยหน่วยแรกมีดรรชนีเป็นศูนย์ และให้ใส่ค่าดรรชนีไว้ภายในวงเล็บปีกกา
ยกตัวอย่างเช่น
บรรทัด 4 อ้างถึงหน่วยที่ศูนย์
บรรทัด 5 อ้างหน่วยที่หนึ่ง
บรรทัด 6 อ้างหน่วยที่ 2 ซึ่งไม่มี เพราะในรายการมีเพียงหน่วยที่ศูนย์ และ หนึ่งผลลัพธ์ได้เป็น Error
โดยหน่วยแรกมีดรรชนีเป็นศูนย์ และให้ใส่ค่าดรรชนีไว้ภายในวงเล็บปีกกา
ยกตัวอย่างเช่น
บรรทัด 4 อ้างถึงหน่วยที่ศูนย์
บรรทัด 5 อ้างหน่วยที่หนึ่ง
บรรทัด 6 อ้างหน่วยที่ 2 ซึ่งไม่มี เพราะในรายการมีเพียงหน่วยที่ศูนย์ และ หนึ่งผลลัพธ์ได้เป็น Error
บรรทัดที่ 8-11 แสดงวิธีอ้างถึงแถวข้อมูลใน Table (ตาราง)
บรรทัด 8 อ้างถึงแถวที่ศูนย์ ได้ผลลัพธ์เป็น Column (ฟิลด์) A และ B
บรรทัด 9 อ้างถึงแถวข้อมูลที่คอลัมน์ A มีค่าเป็นสอง ส่วนบรรทัด 10 อ้างถึงแถวข้อมูลที่ไม่มีอยู่จริงทำให้ได้เออเรอร์
บรรทัด 11 ดรรชนีคลุมเครือ คือมีแถวข้อมูลที่ B = 1 มากกว่าหนึ่งแถว ผลลัพธ์จึงได้ Error เช่นเดียวกัน
บรรทัด 8 อ้างถึงแถวที่ศูนย์ ได้ผลลัพธ์เป็น Column (ฟิลด์) A และ B
บรรทัด 9 อ้างถึงแถวข้อมูลที่คอลัมน์ A มีค่าเป็นสอง ส่วนบรรทัด 10 อ้างถึงแถวข้อมูลที่ไม่มีอยู่จริงทำให้ได้เออเรอร์
บรรทัด 11 ดรรชนีคลุมเครือ คือมีแถวข้อมูลที่ B = 1 มากกว่าหนึ่งแถว ผลลัพธ์จึงได้ Error เช่นเดียวกัน
เพื่อหลีกเลี่ยง Error ภาษา M จัดให้มีตัวกระทำ ? ที่จะให้ค่า Null
ถ้าอ้างถึงหน่วยในรายการที่ไม่มีอยู่จริง ในรูปแบบ x{y}? นั่นคือนิพจน์จะให้ค่า “ Null ” เมื่อตำแหน่งของ y ไม่มีอยู่จริงในตาราง x
โปรดสังเกตบรรทัดที่ 20 ว่าถ้าดรรชนีคลุมเครือ คือ
มีแถวข้อมูลที่ตรงกับดรรชนีมากกว่าหนึ่งแถว ผลลัพธ์จะได้ Error เหมือนเดิม
ถ้าอ้างถึงหน่วยในรายการที่ไม่มีอยู่จริง ในรูปแบบ x{y}? นั่นคือนิพจน์จะให้ค่า “ Null ” เมื่อตำแหน่งของ y ไม่มีอยู่จริงในตาราง x
โปรดสังเกตบรรทัดที่ 20 ว่าถ้าดรรชนีคลุมเครือ คือ
มีแถวข้อมูลที่ตรงกับดรรชนีมากกว่าหนึ่งแถว ผลลัพธ์จะได้ Error เหมือนเดิม
การอ้างถึงหน่วยในรายการจะทำให้เกิดการหาค่าของหน่วยนั้น ๆ หน่วยเดียว หน่วยอื่น ๆ ในรายการจะไม่ถูกประเมินค่า
ยกตัวอย่างเช่น
บรรทัด 22 เฉพาะหน่วยที่ 1 เท่านั้นที่ถูกหาค่า
หน่วยที่ศูนย์ (error “a”) จะไม่ทำงาน
ยกตัวอย่างเช่น
บรรทัด 22 เฉพาะหน่วยที่ 1 เท่านั้นที่ถูกหาค่า
หน่วยที่ศูนย์ (error “a”) จะไม่ทำงาน